
在负面产品评论实际发生之前,如何利用大数据和人工智能对其进行 “捕捉”
在这个电子商务快速发展的时代,在线产品评论对消费者购物行为有着巨大的影响力。
在线评论实质上起到产品或业务本身的实际推荐作用,被视为客户最终购买行为的看门人(参见明镜研究中心的《在线评论如何影响销售》)。
消费者在网上购买商品之前的第一件事就是仔细审查它的评论,并衡量整体情绪。如果平均情绪是负面的,他们会寻找其他选择。另一方面,如果市场人气转向正面,他们就更有可能继续买进股票。因此,评论在产品本身是否被销售方面起着重要的作用。
获得一致的积极评价的困难
对产品的质量以及各种相关因素,如运输速度、包装、下订单的难易程度、在线信息的可获得性等,通常都会给予评价。每天都有数百万人在网上购物,我相信,从我几年前短暂的个人经历来看,从长远来看,不可能得到100%的好评。如果产品和服务是好的,你将不可避免地有杰出的正面评价,但它永远不会100%完美。俗话说,你不可能让每个人都满意。
一个主要是坏的评论可能会严重影响产品的销售。通常情况下,公司的支持部门通过与客户合作来解决问题,从而快速地对负面评论作出反应。然而,这并不能保证客户会回来更新负面评论,即使是在及时交货或退款的情况下。
一些卖家也选择取消他们的上市,如果负面评论攀升过高,但他们失去了销售历史的可见性,这也是一个大的驱动因素,影响销售。
处理负面评论
已经就如何处理负面评论进行了各种研究,在这方面可在网上获得大量相关资料。就我个人而言,当你放大到一定规模后,首先要防止负面评论的出现,而不是等负面评论发布后再加以纠正,这要重要得多,效率也高得多。
当然,人们可以争辩说,实现这一点的明显方法是简单地提供高质量的产品和相关服务,这将自动导致积极的评价。然而,一个经验丰富的网上卖家会同意,迟早,你会遇到一个不高兴的客户。
如果我们以某种方式提前知道客户对他/她的购买不太满意,并且在评论实际被放到网站上之前就有很高的负面评论的可能性,那该怎么办?这个信息对卖家有利吗?卖方是否可以选择对这些信息进行处理,以纠正这种情况并避免负面评论?
避免负面评论对未来的买家来说可能不公平,但是要记住,不管情况如何,客户仍然保留着发布他/她的全部经验的可怕权力。此外,卖家还可以通过展示所采取的补救措施来提高反馈页面的透明度。
如何利用人工智能和大数据“捕捉”潜在的负面评论
在这篇文章中,我想从理论上说明我们怎样才能在这种潜在的负面评论实际发生之前“抓住”它,这样一个诚实的卖家就有机会在它影响业务之前纠正错误。
每当一次购买出错时,典型的顾客可能会做出以下几种反应:
- 再次浏览同一产品的网页,查看评论,看看是否有人有类似的问题,以及是否有卖家对同样的问题作出了有益的回应。
- 与客户服务部门联系,提出投诉。
- 在同一个网站或不同的网站上浏览其他品牌的类似产品。
- 改变他们的购买模式(主要是下降趋势)。
- 继续在相同的网站上订购相同的产品,或者从当地的零售商店购买
- 讨论社交媒体中的不良购买行为。
现在,如果该公司使用在云上的大数据分布式处理引擎上实现的人工智能软件,不断扫描上述所有数据点,寻找客户直接或间接表达对特定购买不满的实例,该怎么办?
实际上,在发布糟糕的评论之前,可能只有几分钟到几个小时的时间。但是,今天超快的光纤互联网速度和蓬勃发展的大数据技术应该为自动化系统提供充足的时间来明智地利用这一时间框架启动纠正行动,从而提高客户满意度并保持相当好的产品评论。
大数据系统是如何工作的
下面是一个非常高层的图表,以及关于这个大数据系统如何工作的步骤:
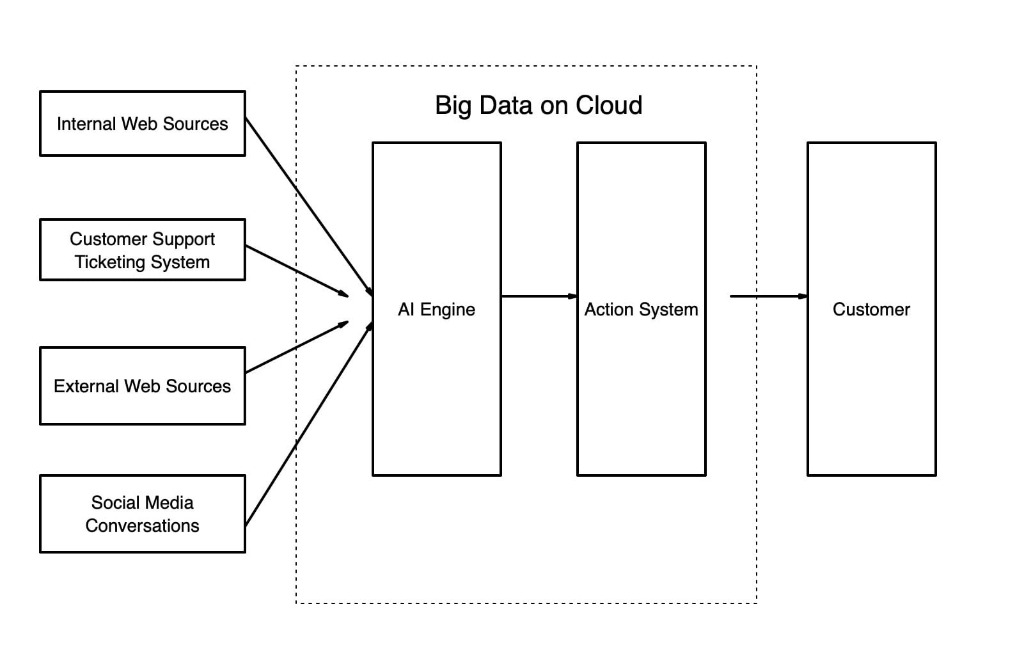
- 来自不同来源的数据包含客户的数字足迹,这些数据定期被提供给大数据分布式处理系统,比如 ApacheSprark或云中的 Hadoop。
- 然后,大数据处理系统将处理这些数据,并迅速提取决策者所需的见解。然后将结果转发到“Action”系统。
- 然后,“Action”系统将分析这个提要,并决定在适当的时候与客户联系,采取可能的补救措施。
卖方根据数据可以采取的行动
大数据系统可能会产生所有需要的结果,但是一旦软件确定存在错误的购买,卖家又能做什么呢?
- 立即与客户联系,索要关于购买的反馈和/或提供解决方案的联系方式(如有)。
- 如果客户要求更换产品,请将客户指向更换部门。
- 为将来的购买提供优惠券或折扣。
你认为当今技术的复杂程度允许这样的实现吗?你认为实现这样一个大数据系统的挑战是什么?
了解更IBM AI解决方案,请访问IIBM数据与人工智能专区
好文章,需要你的鼓励


“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

蚂蚁集团打造的AI“安全警卫“:当智能助手学会看图识险,多模态内容审核迎来新突破
蚂蚁集团AI安全实验室开发的SingGuard是一套多模态内容安全审核系统,能同时理解图片与文字的组合意图,并支持运行时动态传入自定义规则,实现策略自适应的安全判断。


Upstage AI研究员揭示:当AI被要求填写一张完整的表格,它究竟在哪里翻车了?
Upstage AI构建韩语宽度搜索基准KO-WIDESEARCH,测试20个AI系统填写完整结构化表格的能力,揭示AI善于找成员却难以填对每格的核心缺陷。
2020
09/03
15:55
分享
点赞

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
