
浅谈数据治理中的智能数据目录
在数字化转型的战略实施中,很多企业都在搭建自己的业务、数据及人工智能的中台。在同这些企业合作和交流中,越来越体会到数据目录是中台建设的核心和基础。为了更好地提供数据服务,发挥数据价值,用户需要先理解数据和信任数据。 企业拥有什么样的数据,这些数据在哪里,这些数据之间的关系及沿袭,数据是好是坏,这些都是数据目录需要回答的问题。
企业的数据环境具有复杂和多样性,数据分散在成百上千的本地和云端系统之中,其中包括传统的事务性数据库、大数据平台或者数据湖、基于云的市场营销等系统,还有不断涌现的新数据源和应用。人工智能和机器学习可使数据目录 “智能化”,使其具备自动发现,自动数据分类,自动分析和关联的能力,不断满足企业数据管理在处理规模、效率、创新和洞察力等方面的需求。
IBM很早就认识到将机器学习应用到数据管理的重要性,在IBM的Cloud Pak for Data中,机器学习无处不在,遍布数据集成、自动化数据管理、多云数据整合、数据准备、建议和数据洞察,其中Watson Knowledge Catalog致力于改进企业中数据管理者和数据使用者之间的数据流的通信、集成和自动化,被评为机器学习数据目录领导者。
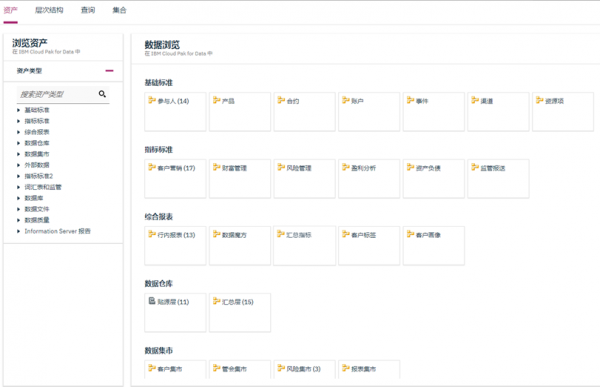
- 自动数据发现,快速构建数据目录
应对企业复杂和多样的数据环境,智能的数据目录可以自动快速地发现数据并进行识别,包括数据的轮廓,数据的业务含义,数据的分类,数据的质量,数据集之间的关系,是否有隐私或者敏感的数据,能快速地创建数据目录,高效地提供数据准备。
- 关联数据资产,完整知识图谱
企业的各种信息,不是孤立的个体,之间存在各种的关系,例如业务分类同业务术语,业务术语同技术资产,业务规则同技术规则及数据资产,数据分类同数据资产,数据资产同数据管家等的关系。对于需要理解数据的用户,希望从任一个关注点出发,获取到与其相关的业务上、技术上、管理上等维度的关联的资产信息。
智能的数据目录,先将企业中存在于系统、流程和集体知识中的各类信息集合在一起,分析并关联,将企业的各类数据资产以关系图的形式展开,对于每个用户,可以从中截取自己关注的片段,并可以随信息的拓展而继续探索和发现新的知识,从而更好地理解数据,丰富自己的数据知识体系。

- 自动数据校验,提升数据质量
在理解数据后,若要使用数据,需要进一步信任数据。数据质量是数据信任的基石,需提供细粒度的量化的数据质量监管和变化追踪,除了内置多种数据质量维度,自动进行数据质量打分外,还需要提供根据数据分类、业务特征、重要性等特定属性自动进行相关的数据规则校验,而不需要考虑数据的来源,大大提高数据管理的效率和范围。
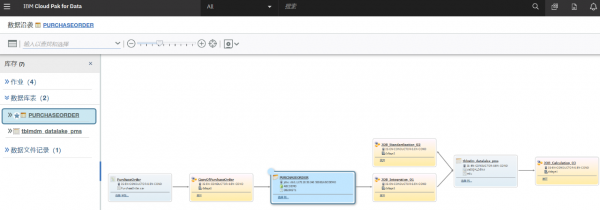
- 自动分析数据沿袭,
用户需要对其数据细致了解,才能对数据更加自信和笃定,才能支撑分析和数据科学。
智能的数据目录能支撑从大量数据源中提取粗粒度—系统和系统之间的,数据集和和数据集合之间沿袭;同时支持细粒度—表和表之间,字段和字段之间的沿袭关系。
- 智能搜索
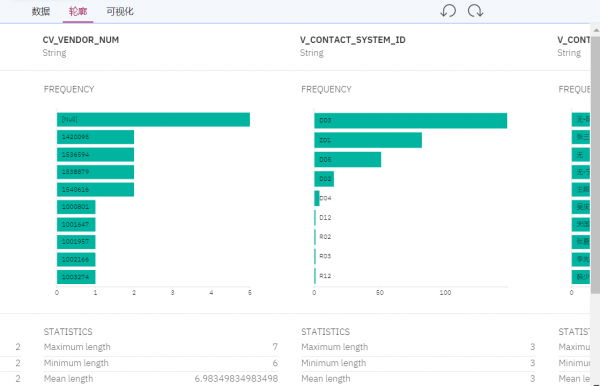
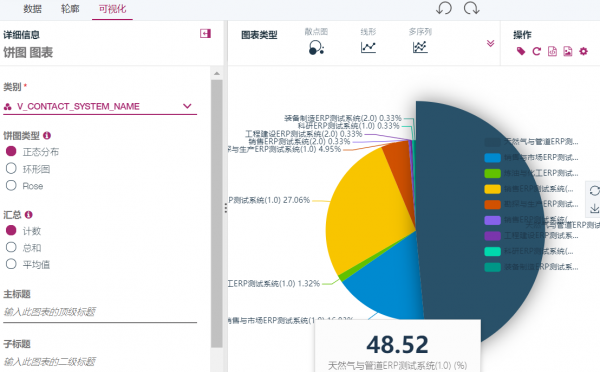
无论是业务用户或者技术用户,无论数据处于企业什么位置,或者搜索时候输入模糊或者近似的信息,用户都能搜索到相应的结果,及大量相关联的信息。这些搜索结果会按照信息相关性从高到底给出。用户还可以在图形化的搜索对象上进行深入的展开和探查。对于搜索到的数据资产,用户可以预览数据,了解数据轮廓,进行数据可视化查看,为后续的数据分析和建模准备数据。
智能的数据目录,帮助用户揭示复杂的数据关系,高效创建可信赖的分析基础平台,从数据采集、数据治理到数据自助服务,提供端到端的一站式平台服务。
详情请访问>>>IBM官网页面了解更多内容
任何问题请拨打免费咨询热线:4006690260 (工作日9:00-17:00)
好文章,需要你的鼓励



牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

美国多源电子患者数据采集方法研究综述
随着医疗数据数字化与互操作性的进步,跨机构纵向患者数据的研究应用成为可能。本研究通过对20位领域专家的访谈,识别出8种数据收集方法,涵盖智能手机应用、结构化数据导出、区域/全国研究查询及聚合数据源等。研究发现,各方法均有其优缺点,无单一最优方案。参与者中介交换方式可绕过复杂治理安排,但存在数据缺口;全国性网络尚不支持研究查询。公共政策的持续推进将对该领域发展起关键作用。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。
2021
08/12
16:39
分享
点赞

最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
