
网易数帆Arctic即将开源,助推湖仓一体落地
8月11日,网易数帆将举办“企业级流式湖仓服务 Arctic 开源发布会”,邀请网易数帆大数据产品线及合作伙伴相关负责人联袂解读对数据技术演进及 Arctic 开源的思考,介绍 Arctic 项目进展、未来发展及社区规划,分享企业湖仓一体实践成果与心得。

数据基础设施发展的脚步从未停歇,当前风头正盛的是湖仓一体(Lakehouse)。
湖仓一体,顾名思义是数据湖和数据仓库优势的结合。随着企业数智化的推进,湖仓一体已不仅仅是开源社区的热点技术,硅谷顶级风头投机构A16Z版图的视野中心,更是众多大数据商业产品家族的重要成员。
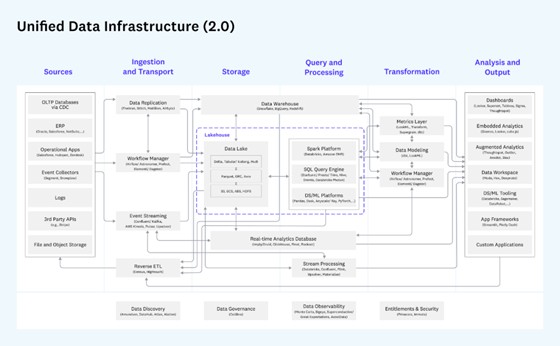
那么,湖仓一体真的会成为企业大数据基础设施的标准?我们是否应当关注这一技术?它的未来是什么?
为什么需要湖仓一体
借用Databricks的定义,湖仓一体平台能同时提供数据仓库的可靠性、强大的治理和性能,以及数据湖的开放性、灵活性和机器学习支持。网易数帆湖仓一体项目负责人马进认为,湖仓一体是接力Apache Hadoop蓬勃生态的新赛道,它的核心特性就是在数据湖上构建事务层,把数据处理和管理高级功能嫁接到低成本数据存储架构上。这是业务需求驱动的架构演进,毕竟业务数据类型及规模不断扩大,而对计算实时性的要求又更高。
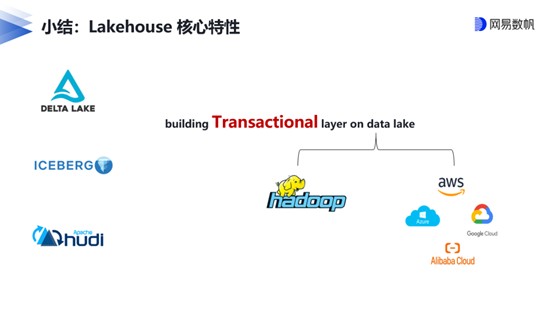
以网易为例,从T+1 离线数据生产,到引入实时化并不断完善,如引入Apache Kudu解决Hive离线数仓在实时数据更新上的不足,形成了流批分割的Lambda架构(这也是业界大数据架构演进的一个缩影),然后数据孤岛、研发体系割裂以及指标和语义的二义性等问题逐渐暴露,这就需要一个更加优雅的统一数据基础设施架构,也就是湖仓一体来解决。基于数据湖开源三剑客(Delta Lake、Apache Iceberg、Apache Hudi)的实现方案,则成为了热门的选择。
网易数帆流式湖仓的创新
尽管在造词法上Lakehouse确实是Data Lake和Data Warehouse的缝合怪,然而要成为生产级的新技术,湖仓一体毕竟不是数据湖和数据仓库1+1=2那么简单。在马进看来,目前湖仓一体方案存在两大不足:一是所读即所写,会产生流式摄取导致海量小文件等问题;二是实时能力不足,比如基于湖仓一体的流计算延迟在分钟级别。
基于此,马进带领团队研发了命名为Arctic的流式湖仓服务,提出了五个设计目标:提供可靠的湖仓一体服务,解决主流湖仓一体的不足,面向更多流批一体的场景,尽可能不要重复造轮子,和寻求代际型解决方案。
技术方案上,Arctic搭建在Iceberg表格式之上,复用Iceberg各种功能,并完全兼容Hive。Arctic面向流场景提供优化的CDC(变更数据获取)和流式更新能力,也可以开放式地集成 MQ、KV 等中间件,向 Flink、Spark、Trino 等主流计算引擎提供流批统一的表服务,以实现数据湖和数仓的统一,并融入实时的能力,流计算延迟可达毫秒级。
由此,Arctic 可视为一个独立的实时数仓服务,用户无需关心数据存储结构、大小和分布,或是否引入其他中间件。
流式湖仓的未来
三十年前,西方学者面对社会变迁发出“历史的终结”的感慨,但历史已经给这一论断打脸。那么,流式湖仓又是否会成为现代大数据基础架构的终点?回顾数据分析领域,先后出现的数据仓库、OLAP、BI、大数据、数据中台等各种方法论,都已融入企业数据生命周期,而底层的Hadoop体系依然在广泛使用,我们有理由相信,流式湖仓服务这一源自业务需求的设计,实现方式可能会升级,但这一思想必将长存于数据基础设施。
从A16Z的全景图我们也可以看到,企业级数据基础设施架构的稳定往往伴随着长时间的沉淀,而Arctic开放的架构及对Hadoop生态的兼容,已经预示着它的生命力。
来源:业界供稿
好文章,需要你的鼓励


轻舟智航在高通最新骁龙芯片上完成城市NOA演示,计划2026年全球量产
擎天智卡(QCraft)近日在高通无锡汽车技术峰会上,展示了基于高通SA8650P骁龙Ride平台的城市领航辅助驾驶(NOA)系统,现场进行了真实城市道路试乘体验。车辆成功应对无保护左转、人车混流、隧道、主辅路切换及拥堵场景。QCraft表示,其QPilot系统已搭载近30款量产车型,累计支持超35亿公里用户驾驶里程,2026年全球量产计划稳步推进。

京东Joy Future Academy等多机构联手揭秘:为何AI“游览“完一圈后,会忘记它刚才看见的东西?
Echo-Memory通过控制变量实验,系统比较了四类AI视频记忆机制,发现"回放质量"与"回访记忆能力"互相矛盾,块状循环结构在语义记忆上表现最佳。

iOS 27将Siri摄像头模式整合进相机应用,大幅优化Camera Control体验
苹果iOS 27将视觉智能功能整合进相机应用,作为全新的Siri模式呈现。此前,长按相机控制按钮会触发视觉智能,与快速点击启动相机形成割裂体验,误触时难以快速退出。新版本中,用户只需在Siri模式与拍照模式间滑动切换,操作更加流畅自然。结合iOS 26将相机控制专注于摄影功能的设计方向,此次改进大幅提升了iPhone专属快门键的使用体验。

腾讯AI Lab出奇招:让大模型“按需取用“记忆,GPU显存占用暴降87%
腾讯等机构提出前瞻稀疏注意力机制LSA,让大模型按需调取历史记忆,GPU显存降至原来13.5%,整体准确率还微升0.6%。
2022
08/02
14:38
分享
点赞

iOS 27将Siri摄像头模式整合进相机应用,大幅优化Camera Control体验
视觉语言模型助力机器人读懂人类情绪
Visa与OpenAI携手推进智能体商务,AI代购值得信赖吗?
iOS 27 大幅优化 Apple Pay 支付卡切换体验
SpaceX正式上市:AI业务成核心驱动力,未来走向如何?
iOS 27终于带来了苹果邮件应用最期待的搜索升级
科技行业5月裁员38242人,创2024年以来最高纪录
iOS 27家庭应用全新功能盘点:AI加持与4K视频升级
父亲节特惠:AirPods Pro 3、M5 MacBook Pro立减220美元及更多优惠
微软押注企业AI竞赛胜负关键在于数据上下文,而非模型算力【AI】
Siri AI 基于 Gemini 模型,但并非 Gemini——这意味着什么?
传统企业补丁管理模式已难以为继
