
阿里云推出单机即可训练百亿参数的中文稀疏GPT大模型,登顶 ZeroCLUE零样本学习榜单
作者:同润、临在
日前,中文语言理解权威评测基准CLUE公布了零样本学习ZeroCLUE的最新结果,阿里云位于该榜单榜首。此次刷榜的模型是阿里云机器学习PAI团队推出的160亿参数的稀疏模型 GPT-MoE,这也是业界首个中文稀疏GPT大模型在该榜单登顶。
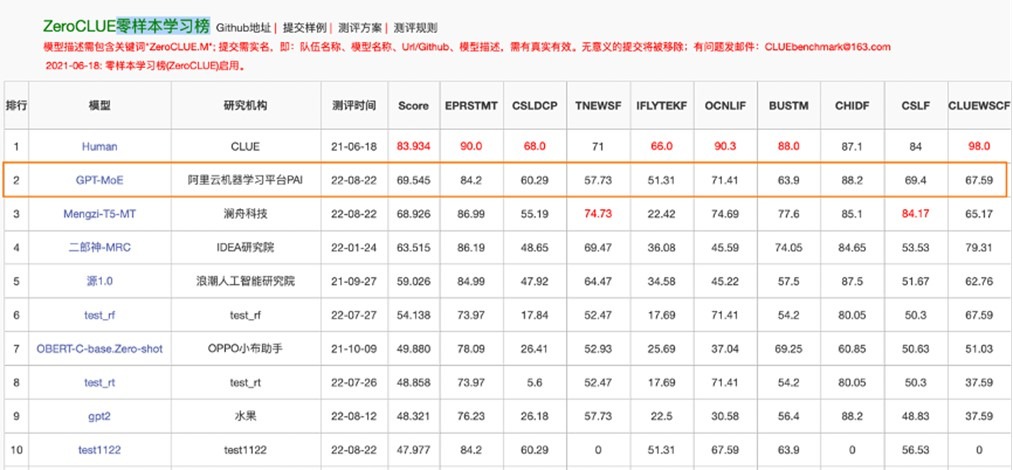
在继去年的Transformer Encoder大模型取得中文小样本学习、英文预训练模型知识量度量冠军后,今年阿里云将大模型技术能力又向前推进了一步。基于MoE稀疏结构,仅用一台A100就把160亿参数量级的多任务通用GPT模型训练成熟。这是通往低成本且高性能多任务通用自然语言理解的重要里程碑。
中文GPT大模型落地主要面临来自两方面的挑战:一方面是中文语言建模的困难,中文可以利用复杂多变的自由组合表达多重含义,这使得中文语言模型比英文在表达效率上难度加倍;另一方面随着模型参数量的不断增加,需要投入的硬件成本越来越高,训练成熟时间越来越长。
以OpenAI推出的1750亿的GPT-3为例,在1024张A100GPU上预估需要34天;因此,能否消耗更少的计算资源以高性价比的方式完成训练和推理是大模型落地亟待解决的难题。
GPT-MoE 模型采用稀疏模型的结构设计,有效缓解了上面提到的两个困难。在刷榜的过程中,从工程到算法沉淀出4点自研核心技术,有强化型稀疏均衡器,领域话术再适应驱动的中文提示语零样本学习,中文复杂任务定向优化,以及阿里云自主研发的transformer训练加速工具Rapidformer,实现了单机A100即可训练160亿参数大模型。
目前,GPT-MoE 模型已在阿里云机器学习PAI EasyNLP项目中开源,和开发者共享中文百亿稀疏GPT大模型技术。
开源项目地址:https://github.com/alibaba/EasyNLP/tree/master/examples/rapidformer
来源:业界供稿
好文章,需要你的鼓励


米拉·穆拉提重返公众视野,谨慎发声
穆拉蒂时隔18个月首次接受重大媒体采访,介绍其创立的Thinking Machines Lab正在开发的"交互模型"。该模型能以200毫秒间隔处理音频、文本和视频流,捕捉人类交流中的中断、修正和停顿。她还谈及OpenAI"政变周"经历,强调行业决策权过于集中的担忧,并回应了公司近期研究人员离职问题,表示这是初创实验室的正常波动。

当AI机器人“自信地“撞向墙壁:STATE16研究院揭示物理AI系统中那些无声无息的致命错误
STATE16研究院这篇综述发现,物理AI系统存在"静默失效"风险——AI以高度自信执行基于错误世界信息的动作,却不触发任何报警,并提出在AI输出与物理执行之间建立独立授权层的框架。

特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
本期《Quick Charge》播客涵盖多个热点话题:特斯拉疑似试图删除FSD欺诈相关证据以规避巨额赔付;卡特彼勒持续推进建筑领域电气化布局;住宅太阳能30%税收抵免即将到期。此外,嘉宾Tom Pacheco就高压系统与电池技术培训展开探讨,强调电动车技术人才培养的紧迫性。节目同时提醒有意安装太阳能的用户尽快行动,可通过EnergySage平台比较多家安装商报价。

当AI学会“边干边学“:UIUC与微软联合打造的网页智能体训练新范式
UIUC与微软联合研发的OpenWebRL框架让4B小模型仅凭400条初始数据,通过在真实网站上边做边学的强化学习方式,在网页智能体基准上超越了用27万条数据训练的竞争对手。
2022
09/02
11:20
分享
点赞

特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
智能体网络流量首超真人访问,"死亡互联网"理论引发新争议
Mentium Technologies Luna-R1 AI芯片入选ET-01星座任务,完成多星部署里程碑
汤道生×姚顺雨:腾讯AI下半场,拼的是“模型×产品”系统能力
AI驱动网络犯罪数量飙升,勒索软件受害者年增389%:Fortinet 发布2026年全球威胁态势研究报告
Inbolt将在Automate展会发布视觉驱动机器人编程新功能
笔记本电脑深度清洁指南:内外兼修焕然一新
加利福尼亚州城市通过全美首个由选民投票决定的数据中心禁令
柴油替代方案:AI数据中心如何利用燃气引擎与蒸汽涡轮供电
AI定义汽车时代,车载以太网可靠性面临全新挑战
安全算法的持续更新正变得愈发困难
轨道数据中心本质上是功能强化的卫星
