
华为云数智融合驱动智慧出行:T3出行的Lakehouse实践
T3 出行是一家致力于成为能够为用户提供“安全、便捷、品质”出行服务的科技创新型企业。截止 2022 年 8 月,T3 出行登陆全国 92 个城市,累计注册用户超 1.1 亿,单日订单峰值破 300 万单。国内权威第三方数据机构 QuestMobile 发布的 2021 中国移动互联网秋季大报告显示,T3出行月度活跃用户(MAU)已经突破 1200 万。
然而随着业务规模快速增长,T3 出行在支撑海量的数据存储与计算时面临着:传统数仓难以解决出行场景的“长尾支付”、TCO(Total Cost of Ownership,总体拥有成本)居高不下、运维成本高且扩展性受限等问题。
为满足业务发展,T3 出行将最初的传统数仓架构改造成业界新兴的 Lakehouse 架构,他们的研发团队在这个过程中走了不少“捷径”,像华为云数智融合产品就为其构建 Lakehouse 提供了不少助力。
在 8 月 16 日主题为“数智融合,云上创新”的华为云大咖说数智融合专场中,T3 出行大数据平台研发负责人杨华分享了 T3 出行的 Lakehouse 架构与实践:
2020年初 Databricks 在一篇论文中正式提出了“Lakehouse”的概念,同期三大开源数据湖框架(Apache Hudi/Iceberg/DletaLake OS版)逐步进入大家的视野。由于 Databricks 的 Lakehouse 是以DeltaLake作为核心 Table Format,因此,在做 Lakehouse 架构构建选型时,这三个框架便成为了优先选项。
在过去的两年里,围绕这三个数据湖框架构建的 Lakehouse 架构正在被越来越多的企业接受并付诸实践。 Lakehouse(国内常称之为“湖仓一体”) 是一个存算分离的架构,存储与计算解耦,各自 scale-out。从存储层来看,借助于纠删码技术,对象存储使得数据的 TCO 与成本得到进一步的降低。从计算层来看,借助于弹性算力,计算资源从以前的长期租赁,变成了按需使用、按需计费的方式。
T3 出行由于从早期就参与 Apache Hudi 社区的源码贡献,因此很早就看到了新兴的这些 Table Format 的优势并开始探索、实践 Lakehouse 架构。借助于华为云 FusionInsight 整体托管能力及其 OBS 对象存储,T3 出行的 Lakehouse 得以稳健地支撑业务的快速增长。
T3 出行的 Lakehouse 架构同时支撑了面向数据分析的 BI 场景以及面向数据智能的 AI 场景,不仅使 TCO 相比技改前降低 20% 以上,更解决了传统数仓难以支持分钟级数据摄取等难题。以一套架构体系支撑了OLAP、AD-Hoc 查询、离线与准实时的数据加工、机器学习训练等BI、AI的典型场景,有效地支撑了“数智融合”。
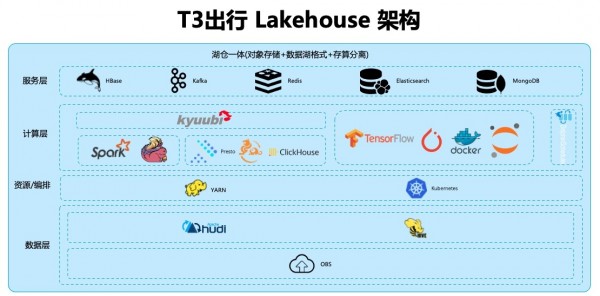
从上面的整体架构图中,我们可以看到:
- 数据层:是一个以对象存储为核心的中心化的存储层,借助于低成本、接近无限横向扩展且支持冷热温分层存储等诸多优势,再结合 Hudi Table Format 在事务语义、文件布局智能管理、多模索引能力、版本化的数据查询等诸多特性的加持,让它成为了 T3 海量数据存储的基础设施;
- 计算层:在 BI、AI 方向下各细分的场景有很多的框架/引擎选型来满足需要。而不同的引擎拥有异构的计算模式与负载,基于数据层中心化的存储,计算层得以跟数据层完全解耦,在此基础上,可以依据不同的计算模式与负载,将他们在物理上拆分为一个个独立的小集群,从而使得计算层各种场景拥有绝对的独立性。
在计算与存储之间引入的 Hudi Table Format,是 Lakehouse 架构的核心,起到“承上启下”的作用。目前国内的主流云厂商都在围绕它封装一些开箱即用的能力,如华为云数智融合平台就是其中之一,除此之外,华为云数智融合平台还提供了更进一步的“融合”能力:
- 三层分离:通过存储 - 缓存 - 内存三层分离,兼顾存储成本和计算性能,让性价比更高,计算更灵活。
- 统一元数据:打破原有大数据、数仓、AI 的数据孤岛,将数据目录、数据权限、事务一致性等能力统一到一个中心点,实现一数多用,让一份数据在多个引擎间自由流动共享,避免数据来回迁移。
- DataOps 和 MLOps 融合:企业不同部门、不同角色可以以擅长的方式敏捷用数。数据工程师可以使用熟悉的工具来调用 AI 能力,使大数据开发和 AI 开发协同起来。例如,让数据工程师用 SQL、Python 交互式 Notebook 做数据清洗、特征工程、模型训练,几行代码就能直接调用平台内预置的 AI 算法,使数据和模型开发周期从天级降为分钟级。
- 全流程的自动化和智能化:华为云数智融合平台将人工智能算法模型应用到数据集成、数据质量、数据建模、数据安全、数据访问控制、数据关联、数据关系和数据洞察的数据全生命周期治理。让繁重的数据治理变得简单。
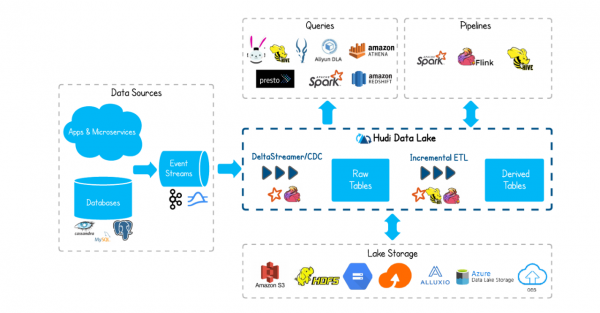
而这一切都是因为Apache Hudi 的生态很丰富(见下图),(左侧)不仅能够支持多种多样的Data Sources 并将数据从其中摄取到 Hudi 表中来。(右侧)而且最底层能够支持主流的、开源的及兼容 HDFS 接口的商业化存储系统。而在存储系统之上的是 Hudi 数据湖框架内核,它支持基于主流计算引擎如 Spark/Flink 以对数据进行 ETL 的能力。在更上层,可以基于 Hudi 框架所映射的表来进行查询与构建数据处理 Pipeline。
下面介绍一下,T3 出行在 Lakehouse 架构下 BI 方向的几个实践。
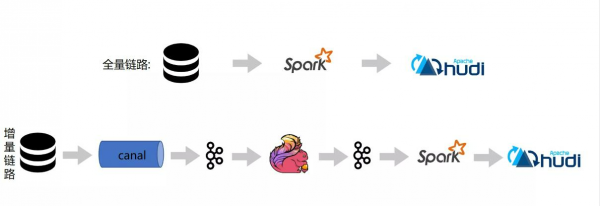
第一个实践是数据入湖。即将业务的关键数据(尤其指核心关系型数据库中“会产生”增量变更的数据)摄取到数据湖中。全量入湖阶段采用Spark将业务库表中的存量数据一次性摄取到 Hudi 表中。增量入湖则主要将业务库的变更数据,借助于 Binlog CDC 的能力,先将 Binlog 采集到 Kafka,然后通过 Flink对分库分表的数据做一层轻粒度的汇聚后通过 Spark 或者 Flink 再将数据增量地回放到数据湖中。
全量与增量在实际操作过程中没办法无缝衔接,而Hudi支持的 Upserts 能力便解决了这个问题,它允许全量与增量衔接过程中的部分重复数据可以被正确地回放到 Hudi 表中并保证了“最终一致性”的语义。
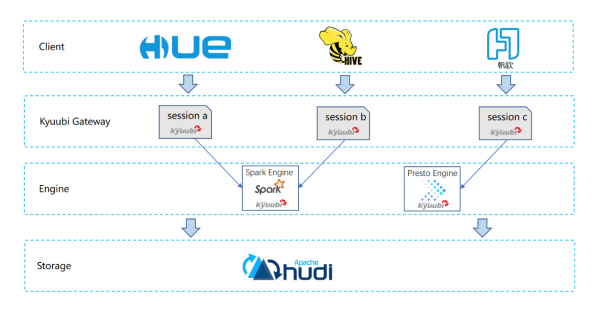
第二个实践是在湖仓中的 ETL。(见下图)最下面的存储层是一些 Hudi 表,这里由于 Hudi 表支持增量查询,因此很多派生表都可以基于原始表来驱动增量 ETL。而在计算层,主要的引擎是 Spark SQL,考虑到湖仓中的表被分层分域,因此 ETL 的资源与作业也需要相应的隔离。经过充分地选型,T3 出行使用了 Apache Kyuubi(Incubating) 框架来解决多租户间的资源隔离问题。
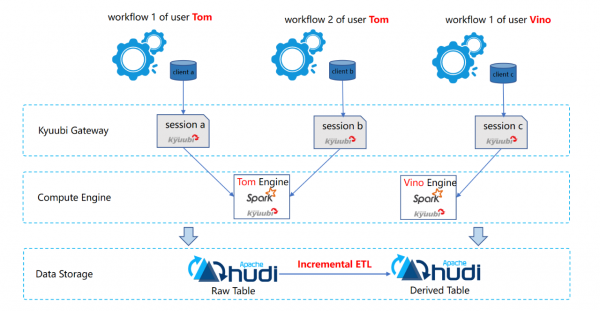
第三个实践是关于湖仓中的 OLAP 以及 AD Hoc 查询。从下图我们看到,整体的分层与上图中的ETL 类似。T3 出行仍然选择将 Apache Kyuubi(Incubating) 作为引擎层之上的 SQL Gateway,并在此之上进行了一些能力扩展。在引擎层,为了支持多样化的查询分析需求,除 Spark 之外,又引入了 Presto、Doris 等查询引擎。Kyuubi 除了对不同租户的资源进行了有效的隔离外,对于同一租户内的不同用户,又可以很好地 share 上下文,从而避免了重复创建的时间与资源开销。
在 AI 方向,T3 出行的很多业务早就实现了算法驱动决策,而这些能力都构建在以 Lakehouse 为基础的机器学习平台上,因此也积累了不少实践。
在计算资源管理方面,借助 Kuberentes 面向不同的训练场景,抽象出了 CPU 集群、GPU 集群,在上层使用微众开源的 Prophecis 的机器学习平台来做资源及机器学习环境的管理,内置了一些开箱即用的算法库及相关环境。最上层提供了 Jupyter 集成开发环境,将算法与数据分析师从环境等问题中解脱出来,从而专注于业务开发。
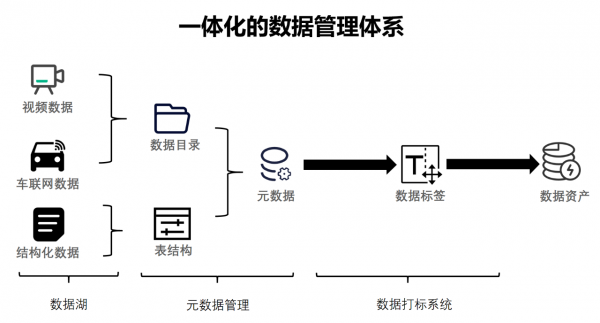
在数据管理方面,构建了面向数据与AI的一体化的数据管理体系。整体上,将数据划分为非结构化的数据与结构化的数据两大类:
- 对于非结构化的数据,如车载终端的音视频数据,采用基于目录的形式进行管理;
- 对于结构化的数据(含部分半结构化),统一以“表”的形式定义 Schema 来进行管理。
T3 出行在这两大类数据基础上,采集描述信息以形成一体化的元数据。之后再对数据统一进行标注、打标签等治理工作,从而形成有价值的数据资产。
由于绝大部分的数据都可以抽象为“表”来进行管理,而他们都基于 Hudi 这一“表格式”。T3 出行在机器学习平台中引入了 Feature Store,Feature Store 的 offline store 的表格式即为 Hudi。借助于 Hudi 一次“提交”可以看作一个“版本”的机制,使特征数据得以被版本化地管理起来。在这样的 Feature Store 基础上结合 CI/CD 体系可以很好地实现业界流行的 MLOps,目前 T3 出行正在这个方向上深度探索。
T3 出行构建的 Lakehouse 架构很好地支撑了当下业务的发展,但其实还有很多需要继续调优的地方。比如,在计算层追求更好的弹性往云原生的方向快速前进、在计算与存储层之间引入高效的缓存机制来降低存算分离带来的性能衰减、统一元数据体系等。
而华为云已经在这些方面做了许多技术探索并形成了能力层与产品化的沉淀。T3出行将持续与华为云一同合作与探索,通过华为云数智融合平台,更好地实现数据与智能的融合与统一,共同赋能智慧出行。 我们有理由相信,在华为云数智融合平台的加持下,会有越来越多的企业能够通过 AI 重新定义数据治理,让数据高效激发出更多 AI 创新能力。
好文章,需要你的鼓励


Glean年收入突破3亿美元,削减AI成本成核心卖点
企业AI搜索公司Glean宣布年度经常性收入(ARR)达3亿美元,较15个月前的1亿美元增长三倍。尽管谷歌、微软、OpenAI等科技巨头纷纷入局企业AI搜索市场,Glean凭借"上下文图谱"技术深度理解企业业务需求,并帮助客户显著降低AI计算成本。该公司提供按用量计费和混合定价两种模式,客户涵盖Databricks、Reddit、Pinterest及三星等企业。Glean上轮融资后估值达72亿美元。

香港中文大学与MiniMax联手破解AI图像描述的“说多错多、说少漏多“困局
香港中文大学与MiniMax提出ClaimDiff-RL框架,将图像描述的AI训练从整体打分升级为逐条核查,有效解决了传统方式导致AI"少说保平安"的问题,同时在多项基准测试上超越Gemini-3-Pro-Preview。

蓝色起源“新格伦“火箭在佛罗里达测试中发生爆炸
杰夫·贝索斯旗下的蓝色起源公司在佛罗里达卡纳维拉尔角进行静态点火测试时,新格伦重型火箭发生爆炸。这是美国历史上最大规模的火箭爆炸之一,也是蓝色起源公司遭遇的最严重失败。所有人员安全,但该事故可能导致新格伦火箭项目长期暂停。此前该火箭已成功完成三次发射,并实现了助推器回收和重复使用。

NTU、HKU等多所顶校联手,让AI同时“多角度看片“——视频理解的并行探针革命
ParaVT是一个由南洋理工等多校联合提出的并行视频工具调用框架,通过让AI同时分析多段视频并引入PARA-GRPO算法解决训练中的格式崩溃与工具跳过问题,在六项长视频理解测试中平均提升约7.9%。
2022
09/16
14:19
分享
点赞

Glean年收入突破3亿美元,削减AI成本成核心卖点
蓝色起源"新格伦"火箭在佛罗里达测试中发生爆炸
智能体AI正在重塑企业架构与Token经济学
堪培拉理工学院如何借助技术革新重塑课堂教学体验
Gemma 4携手Arm:优化端侧AI,加速移动应用体验
制药公司与初创企业如何携手推动AI落地
《星球大战》导演盛赞生成式AI:电影制作的革命性工具
Salesforce借助Informatica布局企业级无头数据管理架构
几乎所有M5 MacBook Air配置现在都降价近200美元
企业用好Agent,关键不在“买一个智能体”|原点Talk 分享会
大模型评测风向变了,Testin云测如何构建企业级AI质量标尺?
因民事养老金管理失误,英国政府拒绝向Capita授予5.63亿英镑合同
