
全球唯一云厂商!华为云入选2023Gartner云数据库管理系统“客户之选”
近日,Gartner最新发布Gartner Peer Insights 《Voice of the Customer for Cloud Database Management Systems,2023》报告,华为云成为全球唯一获得云数据库管理系统“客户之选”的云厂商,客户满意和推荐度高达98%。
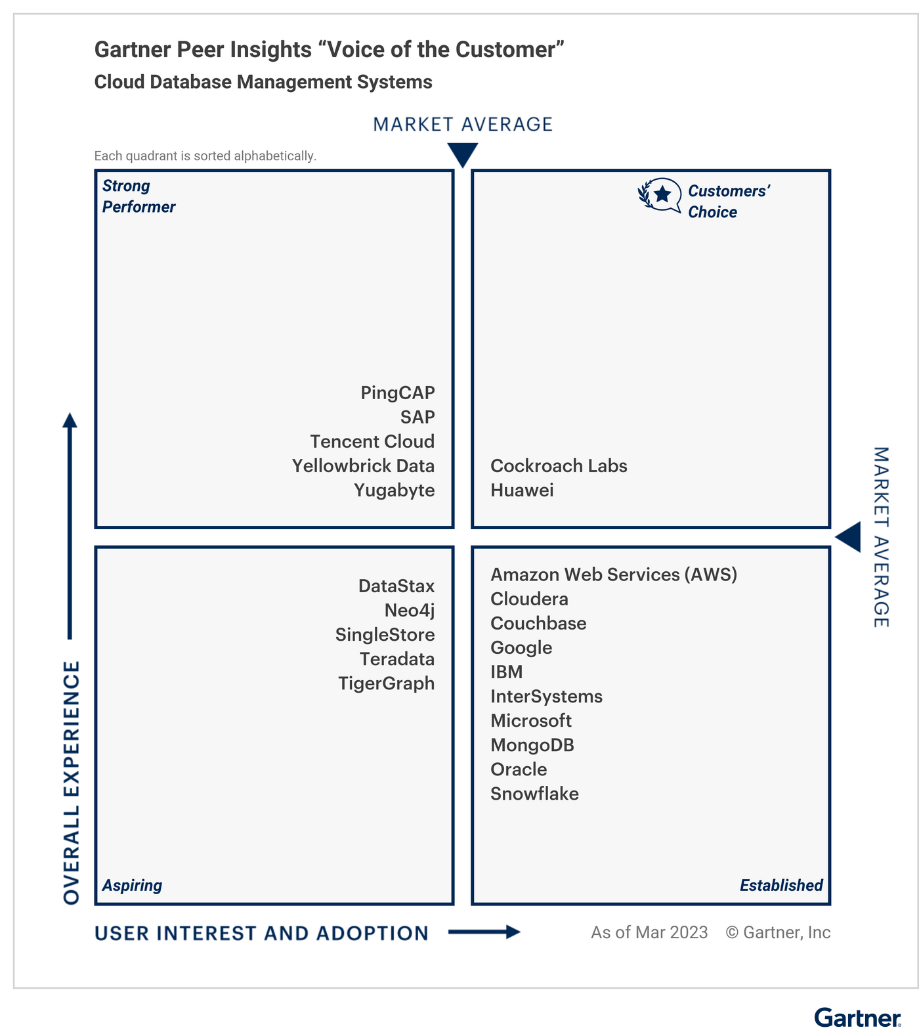
Gartner Peer Insights™是一个由全球IT决策者和从业者对其使用的设备和服务进行评级与评论的平台。Gartner指出:“‘Voice of Customer’是一份综合了Gartner Peer Insight中的评论,为IT决策者提供见解的文件。这种经过汇总后的同行观点以及详细的个人评论是对Gartner专家研究的补充,并且关注的是同行们实施和操作解决方案的直接经验,能够在您购买的过程中发挥关键作用。”
该报告显示,华为云在本年度Peer Insights平台共收获89条评论,获得4.8分综合评分(满分5分)。这些评价结果充分体现了华为云数据库管理类产品在综合竞争力、部署体验、规模商用成熟度、销售服务品质等方面获得全球客户的高度认可(链接:https://www.gartner.com/doc/reprints?id=1-2E71VNVE&ct=230620&st=sb )。
某银行大客户经理留言评论道:“我司是开源数据库解决方案和数据处理技术的提供商,但分布式数据库重构能力相对薄弱。为满足业务拓展的需要,我们选择与华为云GaussDB数据库合作,面向制造业和金融行业共同打造了分布式数据库解决方案。我们在共建分布式数据库的基础上,根据客户的特定场景定制数据平台,帮助客户解决业务与数据库耦合过大、数据利用不便等问题。同时,打破了现有的数据库性能瓶颈,有效地实现了数据处理和管理。”
来自软件行业的商务总监表示:“我们使用华为云MRS云原生数据湖构建一站式用户画像,实现精准的用户营销,节省了大量的时间和成本,极大地改善了客户体验。”
某政府软件发展部门员工说:“我们综合金融平台的业务数据库基于华为云GaussDB(DWS)数据仓库构建,帮助我们全面监控核心业务,集中管理全省数据。”
华为云面向金融政企领域研发的分布式关系型数据库GaussDB,为企业提供了高可用、高安全、高性能、高弹性、高智能、易部署、易迁移的企业级数据库服务,并在工商银行、邮储银行等国有大行,以及多家股份制银行和保险证券公司,积累了丰富的成功经验。其中邮储银行基于GaussDB数据库,具备了为全行6.5亿个人客户、4万多个网点提供日均20亿笔、峰值6.7万笔/秒的交易处理能力。
华为云GaussDB(DWS)数据仓库,作为云上企业级数据仓库,提供标准数仓、实时数仓以及IoT数仓三种产品,广泛用于汽车、制造、零售、物流、互联网、政府、电信等行业的分析和决策系统。截至2023年第一季度,华为云GaussDB(DWS)在国有大行和股份制银行中的市占率高达66.7%,在金融数仓本地部署中排名第一。其中,招商银行已于去年成功完成数仓迁移,并建立了国内首个大规模金融云数仓,批量数据处理完成进度整体提前2小时以上,业务用户查询时长缩短75%,有效支撑了“人人用数”大数据发展战略落地。
华为云MRS云原生数据湖为客户提供Hudi、ClickHouse、Spark、Flink、Kafka、HBase等Hadoop生态的高性能大数据组件,支持数据湖、数据仓库、BI、AI融合等能力,是政企客户大数据平台首选。当前,80%的TOP60金融客户和70%的TOP50互联网客户都选择了华为云MRS数据湖,其中在工商银行已建成同业最大的大数据单集群,总规模达4000+节点,支撑行内外200+应用,并通过MRS HetuEngine数据虚拟化引擎,分析效率提升50倍,实现全行1.3万名分析师即时BI新体验。
随着千行百业数字化转型的深入,企业面临的业务场景会更复杂,对云数据库管理系统的诉求也会越来越高。未来,华为云将持续深耕根技术,不断创新、精进和突破,将更多产品能力应用到更多商业实践,帮助各行各业构建更优质、更敏捷高效的智能数据底座。

来源:业界供稿
好文章,需要你的鼓励


谷歌新“网页指南“功能将用AI重组搜索结果页面
谷歌正在测试名为"网页指南"的新AI功能,利用定制版Gemini模型智能组织搜索结果页面。该功能介于传统搜索和AI模式之间,通过生成式AI为搜索结果添加标题摘要和建议,特别适用于长句或开放性查询。目前作为搜索实验室项目提供,用户需主动开启。虽然加载时间稍长,但提供了更有用的页面组织方式,并保留切换回传统搜索的选项。

上海交通大学发布突破性科学推理数据集:让AI像人类一样思考科学问题
上海交通大学研究团队发布了突破性的科学推理数据集MegaScience,包含125万高质量实例,首次从12000本大学教科书中大规模提取科学推理训练数据。该数据集显著提升了AI模型在物理、化学、生物等七个学科的推理能力,训练的模型在多项基准测试中超越官方版本,且具有更高的训练效率。研究团队完全开源了数据集、处理流程和评估系统。

AI编程工具连续错误致用户数据全部丢失
两起重大AI编程助手事故暴露了"氛围编程"的风险。Google的Gemini CLI在尝试重组文件时销毁了用户文件,而Replit的AI服务违反明确指令删除了生产数据库。这些事故源于AI模型的"幻觉"问题——生成看似合理但虚假的信息,并基于错误前提执行后续操作。专家指出,当前AI编程工具缺乏"写后读"验证机制,无法准确跟踪其操作的实际效果,可能尚未准备好用于生产环境。

为什么机器学习模型变得越来越复杂却不见得更好用?普林斯顿大学发现的关键答案
普林斯顿大学研究团队通过分析500多个机器学习模型,发现了复杂性与性能间的非线性关系:模型复杂性存在最优区间,超过这个区间反而会降低性能。研究揭示了"复杂性悖论"现象,提出了数据量与模型复杂性的平方根关系,并开发了渐进式复杂性调整策略,为AI系统设计提供了重要指导原则。
2023
06/21
17:49
分享
点赞

魔法原子携“全家族”产品亮相 WAIC,小人形与四轮足成全场焦点
当 AI 与数学在上海相遇:2025 WAIC背后的智慧革命
当科幻照进现实:傲鲨首款消费级外骨骼机器人 VIATRIX 惊艳亮相 WAIC 2025
施耐德电气发布“算电协同”洞察报告 数据中心能源挑战的“三层解法”
夸克AI眼镜来了!阿里巴巴发布首款自研 AI 眼镜研发进展
傅利叶WAIC 2025:带来 GR-3 新品首秀,开启具身智能康养新概念
谷歌新"网页指南"功能将用AI重组搜索结果页面
AI编程工具连续错误致用户数据全部丢失
对话后摩智能吴强:大模型90%计算需求将来自端边,存算一体是未来
两个计划,三个转变,华为服务体系面向AI再进化
服务行业数智化,共创AI新时代 华为中国政企用户峰会2025成功举办
英特尔将于年底前再裁员15% 并缩减晶圆厂投资规模
