
软硬件双向驱动 英特尔加速AI on PC落地
以ChatGPT、Claude2、Stable Diffusion、Midjourney等为代表的生成式AI崛起的背后,是大众用户亲眼看到了AI技术切实落地到了实际应用之中,并为工作、创作、创意带来前所未有的效率提升。它与AI1.0时代的卷积神经网络、深度学习等看起来就颇具技术门槛的核心技术相比,显然更接地气,更容易为大众所接受。
毫无疑问,如今的我们正处在人工智能技术发展的关键阶段,它正在逐渐渗透到人类生活、工作、学习的方方面面。而生成式AI作为AI宏观体系中的一次大突破,正以惊人速度改变着自然语言处理、创意生成以及智能助手等领域的实践落地。而在这个过程中,英特尔作为半导体、软件、AI等技术领域的领导者和领先者,正以其强大的软硬件支持,为生成式AI的蓬勃发展构筑核心生态。

·硬件:AI普及的关键是让普通电脑也能轻松跑动各种大模型
一般来说,绝大部分AI相关应用的着力点在GPU,因为它拥有强大的并行计算能力和浮点性能。但是此前在大湾区的一场技术分享会上,英特尔颠覆了我们对于AI计算硬件的认知。
通过构建BigDL-LLM库的方式,英特尔让ChatGPT这样的大语言模型顺利运行在了支持AI加速引擎的第12代和13代酷睿处理器平台上,并通过一系列优化使其速度达到了非常流畅的级别。即便是主打续航、便携能力的轻薄本,也能在16GB及以上内存容量平台中顺利运行最高达160亿参数的大语言模型。而让普普通通的笔记本电脑都能够顺利支持AI应用,这必然会为AI普及构筑出前所未有的坚实基础。
此外,BigDL-LLM库不仅支持ChatGPT一种大语言模型,它还实现了对LLaMA/ LLaMA2、ChatGLM/ChatGLM2、MPT、Falcon、RedPajama等多个大语言模型的支持。而且英特尔还提供了易用的LangChain开源框架、Transformers神经网络API接口,并顺利支持Windows、Linux操作系统,从而为不同平台的开发者们也带来了巨大便利。

此外别忘了,英特尔现在也是高性能GPU领域的参与者,旗下的锐炫GPU不仅拥有应用于大型数据中心、服务器领域的产品,在消费市场落地的锐炫A系列显卡同样能够为生成式AI应用提供可靠的算力支持。因此在Stable Diffusion、Midjourney这样的需要GPU算力的图像生成式AI应用领域,英特尔同样能够提供“专业对口”的硬件支持。如台式机端的13代酷睿i7-13700K处理器加上锐炫A770独显,就能够非常高效地运行Stable Diffusion。
·软件:积极拥抱AI社区通过软件优化提升AI应用体验
如果说硬件为应用落地构建了基础,那么软件就是如何在基础之上构建高楼,而软件层面的优化,则是考虑如何让“高楼”从毛坯变成精装。
一直以来,英特尔在软件领域的投入都十分令人瞩目。通过精心构建软件生态,优化模型性能,英特尔为生成式AI在个人电脑端的应用创造了有利条件。
英特尔积极拥抱AI社区,通过基于OpenVINO PyTorch后端的方案,使得开源模型能够在英特尔的客户端处理器、集成显卡、独立显卡和专用AI引擎上顺畅运行。
同样以生成式AI应用中最火的图形视觉领域为例,英特尔开发了一套专门的AI框架,它可以在开启OpenVINO加速的情况下,仅通过一行代码的安装,就可以加速PyTorch模型运行。此时,就可以让Stable Diffusion Automatic1111 WebUI在集成显卡和锐炫独立显卡上流畅运行。
我们在一台13代酷睿i7-13700H处理器+锐炫Xe核显机器上试着让Stable Diffusion生成一张图片,所提的需求并未太过复杂,总体耗时为44秒,完成速度算是相当快的了,毕竟这是在移动平台的核显上做的图片渲染和生成。
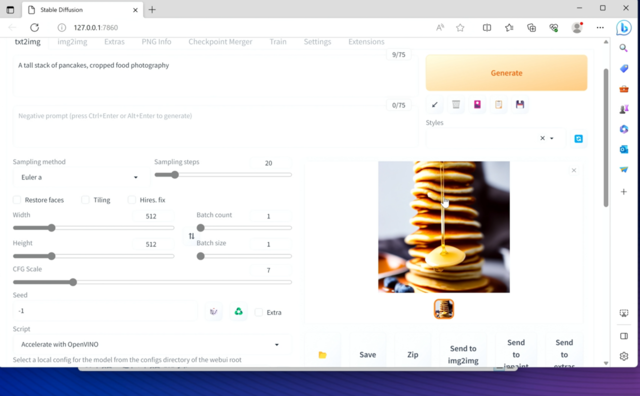
目前,单单是96EU的锐炫Xe核显,就可以支持在Stable Diffusion上运行FP16精度的模型,从而快速生成高质量图片,为内容创作、视觉创意提供便利。
从这一案例可以看出,无论是文字生成图片还是图片生成图片,英特尔通过软件优化、模型优化,将模型对硬件资源的需求尽可能降到最低,从而提升模型的推断速度,确保那些以往需要高性能显卡才能运行的开源模型能够在个人电脑上也能高效运行,这对于AI应用普及同样是意义非凡。
·英特尔大语言模型应用落地12代、13代酷睿电脑全部支持
在8月18日举办的大湾区技术分享会上,英特尔还进一步展示了其软硬件体系在大语言模型应用方面的实际表现。通过集成了ChatGLM2、LLa MA2和Star Coder三个大语言模型的英特尔大语言模型应用Demo,成功展示了这些大语言模型在中文和英文应用方面的表现。
比如我们通过它询问了“AI在PC领域上的应用”,它的首次响应延迟只有215.3ms,也就是在提交问题到AI识别问题,再到开始生成问题答案的过程只有215.3ms,可以说是非常迅速。
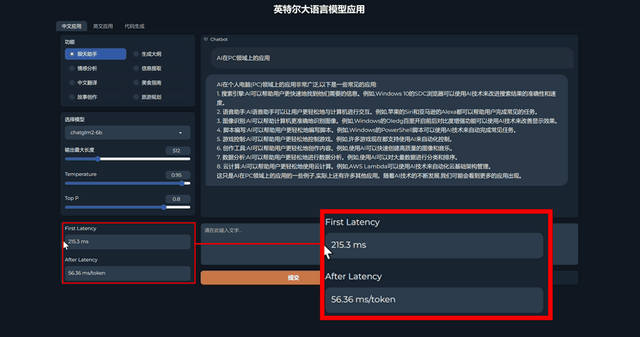
此外可以看到,这款软件集成了中文、英文、代码三种语言环境,对应功能的指向性也很明确。聊天、情感分析、中文翻译、故事创作等等,可以说是涵盖了大语言模型的常见应用。这样的分类可以帮助用户更加明确地向AI提出需求,而如何明确、正确提出需求,本身也是目前AI应用中的难点之一。
我们也试着向AI提出了“和女朋友吵架了怎么哄她”的情感分析需求,首次响应时间为249.8ms,比上一个问题响应慢一些,可见和女朋友的情感问题摆在AI面前,它也需要多加思考一番。
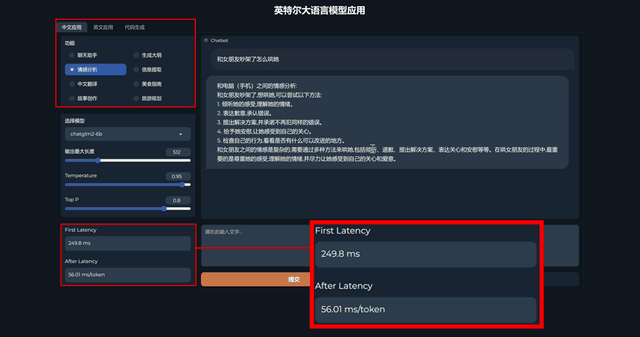
英特尔借助软件端优化和量化操作,使得大语言模型在进行回答时能够以非常快的速度生成答案,并且不影响整机使用流畅性,这同样也是AI应用普及的重要一步。目前英特尔已经发布了这套Demo,任何搭载英特尔12代和13代酷睿的电脑都可以直接安装并进行体验。
·英特尔:AI on PC的核心赋能者
英特尔不仅仅是AI技术的提供者,更是让AI on PC从“PPT”走向实际落地的核心赋能者。
借助支持AI加速引擎的12代、13代酷睿处理器,借助具备高效浮点性能的锐炫GPU等强力硬件,并且快速推出英特尔大语言模型应用Demo以及通过后端优化和OpenVINO加速来更好地支持Stable Diffusion图形视觉领域的AI应用,AI借助PC实现全面普及只是时间问题。
现阶段,大众用户对于生成式AI应用的使用意愿极为强烈,因为它确实能够解决很多实际问题。如提升办公效率、提供辅助设计和创意理念等等,这些应用能够彻底改变人类现阶段的工作、生活方式,激发人们在创作、创意层面的灵感,而硬件性能强大的电脑无疑是最佳载体。
除了已经发布的第12代与13代酷睿之外,英特尔下一代Meteor Lake处理器也将进一步强化对于AI的底层支持,专门设计的NPU将为AI应用带来更加高效的体验。
在生成式AI集中落地的大潮中,英特尔是一个不可或缺的关键因素。从强劲性能的硬件支持到模型优化的软件技术,英特尔为生成式AI的发展提供了全方位支持。在英特尔的引领下,生成式AI与PC将实现惊人的化学反应,为人类带来更智能、更富创意PC使用体验。
来源:业界供稿
好文章,需要你的鼓励


AI将在2030年前渗透所有IT工作——但不会取代所有IT岗位
Gartner预测,到2030年所有IT工作都将涉及AI技术的使用,这与目前81%的IT工作不使用AI形成鲜明对比。届时25%的IT工作将完全由机器人执行,75%由人类在AI辅助下完成。尽管AI将取代部分入门级IT职位,但Gartner认为不会出现大规模失业潮,目前仅1%的失业由AI造成。研究显示65%的公司在AI投资上亏损,而世界经济论坛预计AI到2030年创造的就业机会将比消除的多7800万个。

Meta与特拉维夫大学联手打造VideoJAM:让AI生成的视频动起来不再是奢望
Meta与特拉维夫大学联合研发的VideoJAM技术,通过让AI同时学习外观和运动信息,显著解决了当前视频生成模型中动作不连贯、违反物理定律的核心问题。该技术仅需添加两个线性层就能大幅提升运动质量,在多项测试中超越包括Sora在内的商业模型,为AI视频生成的实用化应用奠定了重要基础。

AI工厂引领产业变革:芯片巨头如何重塑计算基础设施
人工智能正从软件故事转向AI工厂基础,芯片、数据管道和网络协同工作形成数字化生产系统。这种新兴模式重新定义了性能衡量标准和跨行业价值创造方式。AI工厂将定制半导体、低延迟结构和大规模数据仪器整合为实时反馈循环,产生竞争优势。博通、英伟达和IBM正在引领这一转变,通过长期定制芯片合同和企业遥测技术,将传统体验转化为活跃的数字生态系统。

上海AI实验室重磅发布:让AI看图“说人话“的神奇训练法,解决多模态AI与人类价值观对齐难题
上海AI实验室发布OmniAlign-V研究,首次系统性解决多模态大语言模型人性化对话问题。该研究创建了包含20万高质量样本的训练数据集和MM-AlignBench评测基准,通过创新的数据生成和质量管控方法,让AI在保持技术能力的同时显著提升人性化交互水平,为AI价值观对齐提供了可行技术路径。

