
华为云FusionInsight携手国家级大数据实验室,探索时序数据库IoTDB
7月30日,在华为云TechWave数据使能专题日上,清华大学软件学院院长、大数据系统软件国家工程实验室执行主任王建民教授和华为云FusionInsight技术专家发表演讲,共同分享了华为云FusionInsight技术团队携手国家级大数据实验室,探索时序数据库IoTDB。

清华大学软件学院院长、大数据系统软件国家工程实验室执行主任王建民教授
传统时序数据库面临的痛点与挑战
随着物联网的飞速发展,工业领域中的设备、机器、传感器产生海量数据,例如物联网设备的温度、湿度、速度、压力、电压、电流以及证券买入卖出价等,且这些数值还将随着时间演进而不断变化,传统数据库在对这些带时间标签(按照时间的顺序变化,即时间序列化)的数据进行存储、查询、分析等处理操作时捉襟见肘,通用数据库无法满足所有需求、海量时序数据存储查询慢、工业级时序数据库产品需要高可用、存储成本居高不下、使用难等问题。
IoTDB一套引擎打通云边端
IoTDB是由清华大学软件学院发起主导、华为深度参与的轻量级、高性能时间序列数据库,该项目于2018年11月正式开源,支持物联网数据收集、存储、查询与分析一体化的数据管理,支持“云-边-端”一体化部署与集成,适用于高端装备管理、工厂设备管理、高速网联设备管理等多种工业应用场景。
IoTDB时序数据库聚焦海量杂时序数据的处理,具有“专、快、稳、省、易”五大特点,解决通用数据库和列式数据库在超大规模复杂时序场景的功能短板和性能瓶颈,轻松应对海量负责时间序列数据的处理,并能实现一套引擎打通云边端的时序数据分析。
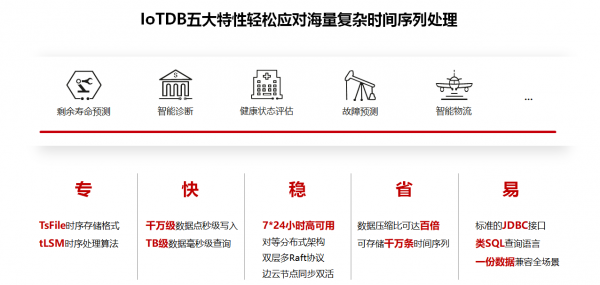
专,IoTDB总结了过去十年来在工业应用中遇到的典型需求,如千万级超大规模测点处理、乱序处理、多序列对齐、序列分割、子序列匹配、旋转门压缩、降采样存储等专业场景,有针对性地设计了TsFile专业时序存储格式和tLSM时序处理算法,解决了通用数据库在超大规模复杂时序场景的功能短板和性能瓶颈;
快,时序数据库面临的场景要求数据采集频率高、每秒上万次采集,数据存储周期长,时间跨度大,IoTDB可实现单台服务器千万级数据秒级写入,十亿量级数据毫秒级聚合检索;
稳,工业级的时序数据库产品需要具备高可用的基本保障,才能达到商用的要求,IoTDB创新性研究了国际内外的算法,通过对等分布式架构、双层多Raft协议、边云节点同步双活等机制实现高可用,满足7*24小时的零故障运行;
省,成熟的工业时序数据库产品,存储成本在时间序列里占很大的比例,IoTDB解决工业客户对IT成本的敏感性,针对性的做了高压缩比算法,包括有损压缩和无损压缩,针对不同场景做自动识别,实现全量数据的低成本持久存储;
易,产品的易用性是成熟商用产品的基础指标,IoTDB采用类SQL语句,降低客户使用成本,同时为客户提供查询、存储、分析全生命周期的一体化解决方案,降低客户使用门槛。
IoTDB开源探索软件创新之路:产学研用
目前,IoTDB已在众多应用场景中进行了落地实践。例如,全国多个城市采用IoTDB管理地铁监控数据,在传统时序处理方案中,端、边、云采用不同的技术栈,异构的技术栈带来数据处理的复杂性,原本需要13台服务器完成的业务场景,目前仅需一台IoTDB服务器就可解决,测点的采样时延也从原来的500ms降至200ms,日增4140亿数据点管理,有效提升资源利用率。
IoTDB时序数据库不仅解决了海量复杂时间序列数据的处理,同时也为软件创新探索出新的模式。王建民教授在演讲中提到:“未来,清华大学将依托大数据国家工程实验室,持续与华为为代表的大批优秀企业,探索产学研用的中国软件创新之路,实现企业与组织、代码与代码的丝丝相扣,让我们共同期待即将发布的MRS IoTDB时序数据库。”
华为云FusionInsight MRS一架构三湖释放海量数据价值
MRS IoTDB是华为云FusionInsight MRS云原生数据湖中的时序数据库组件,近期将在FusionInsight8.1.0版本重磅推出高性能企业级时序数据库。华为云FusionInsight MRS可让客户在一个架构实现离线数据湖、实时数据湖、逻辑数据湖三种数据湖和集市能力,实现海量数据接入、治理、存储、分析和多模计算等场景,助力政企客户实现一企一湖、一城一湖,业务洞见更准,价值兑现更快。
目前,华为云FusionInsight MRS云原生数据湖携手800+生态伙伴,已服务于3000+政企客户,广泛应用于政务、金融、运营商、能源、医疗、制造、交通等行业。
来源:业界供稿
好文章,需要你的鼓励


Musixmatch更新支持CarPlay实时歌词显示
热门第三方歌词应用Musixmatch发布重大更新,现已支持在CarPlay上实时显示歌词。该功能通过CarPlay的Live Activities实现,收听Apple Music或Spotify时,歌词将以动态形式呈现在CarPlay屏幕上。此次更新同时新增Apple Watch歌词支持。Musixmatch应用免费下载,但实时歌词功能需订阅Premium会员,年费为35.99美元。

Layer 6 AI与多伦多大学联手:当AI开始给AI阅卷,谁来监考这位“监考老师“?
RankJudge是一套自动化基准测试生成系统,通过向多轮对话注入可控缺陷,评测AI评判模型的真实辨别能力,覆盖21个前沿模型与三个专业领域。

ChatGPT移动端现可远程启动Windows版Codex
OpenAI近日更新了ChatGPT移动应用,继本月初支持远程控制Mac版Codex之后,iPhone和Android用户现在也可以远程启动并操控Windows版Codex。此次更新还带来了"Computer Use"功能和远程控制能力,同时iOS端Codex远程控制稳定性得到提升,移动端体验进一步向桌面端靠拢。此外,Mac版Codex新增了Appshots功能,支持在锁屏和睡眠状态下维持远程访问。

阿姆斯特丹大学研究团队打破图像生成壁垒:让AI同时“读图“又“读文“,无需任何额外训练
阿姆斯特丹大学提出VCF方法,让Stable Diffusion在生成图像时同时接受图片与文字双重引导,无需重训底层模型,仅靠240万参数翻译官实现跨模态特征融合。
2021
08/02
10:17
分享
点赞

微软批评不负责任的漏洞披露行为
AI智能体会将权限控制推回数据库层吗?
AI可观测性:CIO如何消除组织盲区
微软Build 2026大会:值得期待的内容
英伟达200亿美元"非收购"后,AI芯片初创公司Groq寻求6.5亿美元融资
你听过这些AI术语并点头附和,现在让我们彻底搞懂它们
戴尔营收暴增88%,乘上企业AI浪潮
谷歌云端硬盘为高端安卓设备推出强大的文档扫描功能升级
迪士尼"双子星计划"并非AI项目,而是关停Hulu应用的计划
Musixmatch更新支持CarPlay实时歌词显示
ChatGPT移动端现可远程启动Windows版Codex
智能家居新突破:SwitchBot按钮推手原生支持Apple Home
