
关于Data Lake的概念、架构与应用场景介绍
作者 | 弘锐
数据湖(Data Lake)概念介绍
什么是数据湖(Data Lake)?
数据湖的起源,应该追溯到2010年10月,由 Pentaho 的创始人兼 CTO, James Dixon 所提出,他提出的目的就当时历史背景来看,其实是为了推广自家产品 Pentaho。当时核心要解决的问题是传统数据仓库报表分析面临的两个问题:
· 只使用一部分属性,这些数据只能回答预先定义好(pre-determined)的问题。
· 数据被聚合了,最低层级的细节丢失了,能回答的问题被限制了。
技术概念的提出,本质都是为了业务场景服务的,是为解决某类特定场景的问题。
而我们当前所讨论的数据湖,已经远远超过了当初 James Dixon 所定义的数据湖,各厂商之间也对数据湖有了更多的不同定义。
· Wikipedia
· A data lake is a system or repository of data stored in its natural/raw format, usually object blobs or files. A data lake is usually a single store of data including raw copies of source system data, sensor data, social data etc., and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning.
· A data lake can include structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and binary data (images, audio, video).
· A data lake can be established "on premises" (within an organization's data centers) or "in the cloud" (using cloud services from vendors such as Amazon, Microsoft, or Google).
“数据湖是一类存储数据自然/原始格式的系统或存储,通常是对象块或者文件。数据湖通常是企业中全量数据的单一存储。全量数据包括原始系统所产生的原始数据拷贝以及为了各类任务而产生的转换数据,各类任务包括报表、可视化、高级分析和机器学习。
数据湖中包括来自于关系型数据库中的结构化数据(行和列)、半结构化数据(如CSV、日志、XML、JSON)、非结构化数据(如 email、文档、PDF 等)和 二进制数据(如图像、音频、视频)。
数据湖可以构建在企业本地数据中心,也可以构建在云上。”
· AWS
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
“数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。”
· 微软
Azure Data Lake includes all the capabilities required to make it easy for developers, data scientists, and analysts to store data of any size, shape, and speed, and do all types of processing and analytics across platforms and languages. It removes the complexities of ingesting and storing all of your data while making it faster to get up and running with batch, streaming, and interactive analytics.
“Azure 的数据湖包括一切使得开发者、数据科学家、分析师能更简单的存储、处理数据的能力,这些能力使得用户可以存储任意规模、任意类型、任意产生速度的数据,并且可以跨平台、跨语言的做所有类型的分析和处理。数据湖在能帮助用户加速应用数据的同时,消除了数据采集和存储的复杂性,同时也能支持批处理、流式计算、交互式分析等。”
· 阿里云
“数据湖是统一存储池,可对接多种数据输入方式,您可以存储任意规模的结构化、半结构化、非结构化数据。数据湖可无缝对接多种计算分析平台,根据业务场景不同,可以选择相应的计算引擎对数据湖中存储的数据进行数据处理与分析,从而打破孤岛,挖掘业务价值。”
综上所述,不同厂商对数据湖都有不同的一些描述和理解,但从上面我们可以看到,大家也有一些共通点:
· 统一的数据存储,存放原始的数据。
· 支持任意结构的数据存储,包括结构化、半结构化、非结构化。
· 支持多种计算分析,适用多种应用场景。
· 支持任意规模的数据存储与计算能力。
· 目标都是为了更好,更快的发现数据价值。
关于 Data Lake 每个人都有自己不同的理解,它是一套解决问题的理念,从根本上解决了业务场景所遇到的一些问题,在解决问题的过程中,技术实现上会有一定的差异与不同。
数据湖应该具备哪些能力
数据湖本身其实是一套解决方案,它是为企业的业务诉求服务的,是为发现数据价值提供的一套数据解决方案,那么在这套解决方案里它应该具备怎么样的一些能力,才能满足业务需求呢?
数据存储
· 统一存储系统
数据需要集中存储在一个存储系统中
· 支持海量数据
存储系统需要支持海量数据的存储,并且需要具备可扩展的特性,以支持海量数据的存储及性能要求。如 HDFS、AWS S3、Aliyun OSS 等。
· 任意类型数据
可以支持任意数据类型的存储,包括结构化、半结构化、非结构化的数据。
· 原始数据不变
数据应该在整个数据湖中保持最原始的一份数据,它与原始数据完全一模一样。
数据分析
· 支持多种分析引擎
可以通过多种引擎对湖上数据进行分析计算,例如离线分析、实时分析、交互式分析、机器学习等多种数据分析场景。
· 计算可扩展性
计算引擎需要具备可扩展的能力,具备随数据量不断变大、业务不断增长的弹性数据分析的能力。
· 存储与计算分离(云上)
在云上,大家现在都实现了存算分离的数据湖架构,它让存储和计算分别插上了翅膀,可以灵活的进行资源伸缩,大大节省了成本。但在云下 HDFS 架构下,它并不是一个必备能力,因为硬件成本是相对固定的。
数据湖管理
上述的数据存储和数据分析是数据湖必须具备的基本能力,但是就一个解决方案来说,如果要实际解决业务问题,仅仅是基础能力,并不足以将其应用落地,甚至会变为可怕的数据沼泽。所以在数据湖解决方案中,还需要结合一系列的数据湖上的管理能力,帮助大家管理和识别数据湖中的数据。这些能力包括:
· 多样化的数据入湖
需要具备把各种数据源接入集成到数据湖中的能力,作为数据湖构建的第一步,其意义不言而喻。
· 元数据管理
提供统一的元数据能力,可以快速发现数据湖上的元数据,并可对元数据进行管理和优化,避免数据湖成为数据沼泽。
· 数据安全
对数据可以进行细粒度的权限管控,为企业的数据湖加上安全的锁。更丰富的能力还应该支持敏感数据脱敏,数据加密,标签权限,操作审计等能力。
· 数据质量
数据质量是对湖内数据正确性、合理性监控的一种能力,及时发现数据湖中数据质量的问题。为有效的数据探索提供保障。
· 数据探索
可提供在线的数据探索能力,可以满足日常对湖内数据进行快速探索和简单查看的能力,便于更好的管理湖内的数据。
数据湖能解决哪类问题
· 数据分散,存储散乱,形成数据孤岛,无法联合数据发现更多价值
这方面来讲,其实数据湖要解决的与数据仓库是类似的问题,但又有所不同,因为它的定义里支持对半结构化、非结构化数据的管理。而传统数据仓库仅能解决结构化数据的统一管理。
在这个万物互联的时代,数据的来源多种多样,随着不同应用场景,产出的数据格式也是越来越丰富,不能再仅仅局限于结构化数据。如何统一存储这些数据,就是迫切需要解决的问题。
· 存储成本问题
数据库或数据仓库的存储受限于实现原理及硬件条件,导致存储海量数据时成本过高,而为了解决这类问题就有了HDFS/对象存储这类技术方案。数据湖场景下如果使用这类存储成本较低的技术架构,将会为企业大大节省成本。结合生命周期管理的能力,可以更好的为湖内数据分层,不用纠结在是保留数据还是删除数据节省成本的问题。
· SQL 无法满足的分析需求
越来越多种类的数据,意味着越来越多的分析方式,传统的 SQL 方式已经无法满足分析的需求,如何通过各种语言自定义贴近自己业务的代码,如何通过机器学习挖掘更多的数据价值。
· 存储/计算扩展性不足
传统数据库等在海量数据下,如规模到 PB 级别,因为技术架构的原因,已经无法满足扩展的要求或者扩展成本极高,而这种情况下通过数据湖架构下的扩展技术能力,实现成本为0,硬件成本也可控。
· 业务模型不定,无法预先建模
传统数据库和数据仓库,都是 Schema-on-Write 的模式,需要提前定义 Schema 信息。而在数据湖场景下,可以先保存数据,后续待分析时,再发现 Schema,也就是 Schema-on-Read。
LakeHouse 与数据湖
Lakehouse 概念由 Databricks 公司提出,更多内容大家可以阅读:https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
Lakehouse 是一种新的数据技术架构,它在数据湖的基础之上,吸收了数据仓库,数据库的一些特性。这些特性最核心的一个特性是对 ACID 的支持。
Lakehouse 方案简化了整个数据链路,并提高了数据链路的实时性。它从原来的 Lambda 架构,升级到了 Kappa 架构:

从上述 gartner 报告来看,无论是开源社区还是云厂商之间,对于 Delta Lake 都已经有了成熟的解决方案,但 Lakehouse,目前一些技术还是初步应用阶段,但从去年开始已经很多公司将其逐步应用到了各自的业务系统中,并为业务带来了更多价值。从后续我们的应用场景案例中大家也可以看到关于开源的湖格式 Delta Lake/Hudi/Iceberg 的一些具体应用。湖格式为大家带来了更多的可能,更多人愿意尝试,相关技术讲解可参考我们后续的系列文章。
DataWarehouse & Data Lake & LakeHouse 不同维度对比
下图是从各个维度对三种架构的对比,方便我们更好的理解他们的差异以及解决的问题。

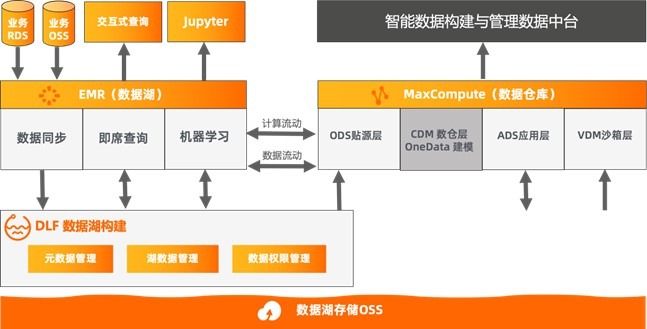
基于阿里云体系的云原生数据湖架构
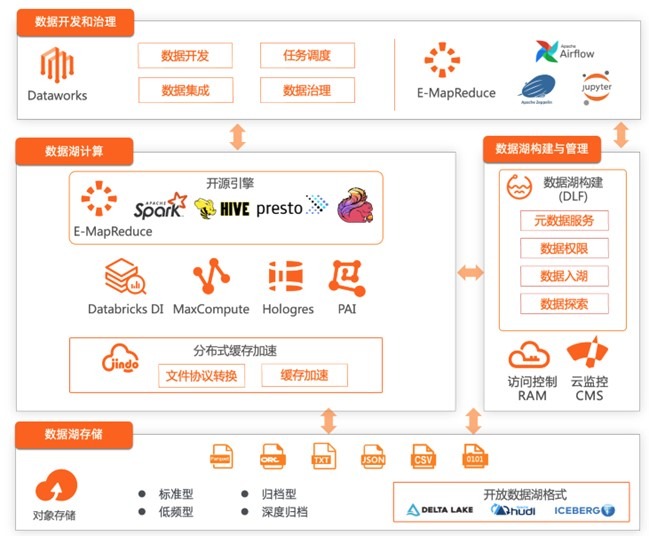
· 数据湖存储
基于阿里云OSS 产品,可以为数据湖提供稳定的存储底座,它具备高可靠、可扩展、已维护、高安全、低成本、高性能等特点。并提供了版本控制,生命周期等能力。
· 数据湖计算
阿里云的大数据分析引擎都支持 OSS 对象存储,如果您使用开源体系,可以使用 E-MapReduce 产品,它为您提供了开源 Spark/Hive/Trino/Flink 等计算能力。如果您喜欢全托管的服务,可以使用 MaxCompute/Databricks/Hologres/Flink 等计算产品。
JindoData 是阿里云开源大数据团队自研的数据湖存储加速套件,面向大数据和 AI 生态,为阿里云和业界主要数据湖存储系统提供全方位访问加速解决方案。JindoData 套件基于统一架构和内核实现,主要包括 JindoFS 存储系统(原 JindoFS Block 模式),JindoFSx 存储加速系统(原 JindoFS Cache 模式),JindoSDK 大数据万能 SDK 和全面兼容的生态工具(JindoFuse、JindoDistCp)、插件支持。
· 数据构建与管理
阿里云数据湖构建(Data Lake Formation,DLF)是一款全托管的快速帮助用户构建云上数据湖的服务,产品为云原生数据湖提供了统一的元数据管理、统一的权限与安全管理、便捷的数据入湖能力以及一键式数据探索能力。用户可以通过快速完成云原始数据湖方案的构建与管理,并可无缝对接多种计算引擎,打破数据孤岛,洞察业务价值。
结合访问控制与云监控两款产品,可以为数据湖提供用户管理、权限控制、监控审计等能力。
数据集成可以通过 Dataworks 的数据集成能力,DLF 的数据入湖,以及 Flink 产品的 CDC,完成数据的全链路入湖,支持多种数据源的数据入湖能力。
离线作业的数据开发、任务调度可以使用 Dataworks 产品实现,也可以使用开源系列方案如 airflow+zeppelin/jupyter 等实现。
实时作业的数据开发、任务调度管理可以通过 Flink 产品实现。
数据质量、数据治理等功能可以通过 Dataworks 产品实现。
数据湖的构建、管理与应用过程

数据湖的应用场景
传统大数据平台升级为数据湖架构
· 传统IDC机房的大数据平台存在以下的问题:
· 物理机自建集群,日常运维成本较高
· 业务发展迅速, 流量压力, 计算压力不断增加,资源不足,补货周期长
· 数据分散,不同项目之间标准混乱
· 数据定义模糊,没有有效分层,分析使用困难
· 解决方案
· 存量数据通过 Jindofs 迁移到阿里云的OSS
· 基于 EMR+DLF 构建整个数据平台的基础服务
· 使用 EMR 弹性伸缩满足计算量需求
· 使用 DLF 快速构建数据湖所需服务
· 接入 Druid、Hologres、Impala 为上层数据应用提供有力的支持
· 业务价值
· 极大的减少了运维成本, 运维人员减少30%
· 使用 EMR 弹性伸缩大大缩减了计算成本,减少10%-20%
· 通过 Jindofs+OSS 归档存储,减少10%-20%存储成本
· 构建统一的数据标准, 对数据进行分层, 极大的提升了业务方使用效率

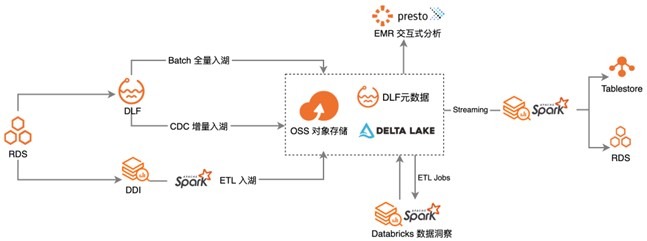
新零售公司全托管数据湖
· 业务难点:
· 线下 Hadoop,组件多,平台运维困难、成本高
· 数据开发、运维难度大,任务稳定性差
· 缺乏健全的安全体系
· 解决方案与业务价值:
· 统一存储:对象存储 OSS,可存储任意规模的数据,可对接业务应用、各类计算分析平台
· 数据湖构建与管理:数据湖构建 DLF,解决数据入湖、统一元数据管理、统一权限控制等关键问题
· 数据湖格式:Deltalake,该格式支持数据的增量更新和消费,从而避免了使用 Lamda 架构的两条链路来支持离线和实时的数据计算
· 数据分析计算引擎:DDI 数据洞察+EMR-Presto 交互式分析,在保证软件产品功能和性能领先的基础上,提供了全托管免运维的服务,同时有极高的 SLA 保证
· 数据开发与调度:EMR Studio 是 E-MapReduce 用于开源大数据开发场景的集群类型,提供交互式开发、作业提交、作业调试和工作流一站式数据开发体验
数据流程:
整体架构图如下:
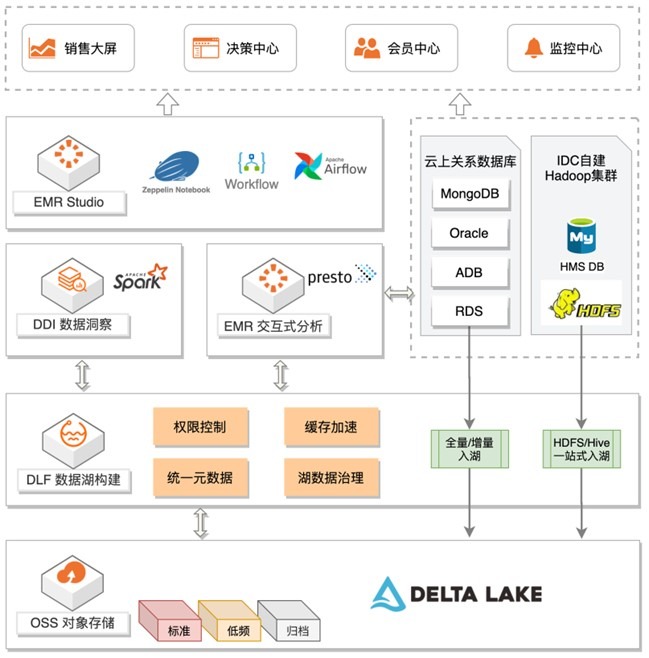
广告行业应用
· 业务难点
· 存算不分离,无法进行灵活指的组件升级,很多新的组件特性没法使用
· 存储在本地盘上,运维难度搞,有坏盘的经历。存储成本高,没法做冷热分层
· 元数据管理在单一的集群上,快集群使用不便,集群稳定性直接影响元数据服务稳定性流批不分离,相互干扰,带来作业稳定性问题
· 解决方案与业务价值
· 存算分离,简化了价格,随时可以升级最新版本,使用Flink, Hudi的最新特性
· 对存储在 OSS 上的数据进行冷热分层,节约成本
· 使用 DLF,进行元数据管理,同时管理数据权限。同时快速支持Flink, Hudi等新特性
· Hbase 使用 Jindo Block 模式,方便扩容
· Flink 和 Hbase 等业务分离,提高了业务的稳定性
· 使用 Hudi 的数据湖格式,实现了数据的快速插入,支持了快速的元数据变更,也能支持业务的准实时分析场景
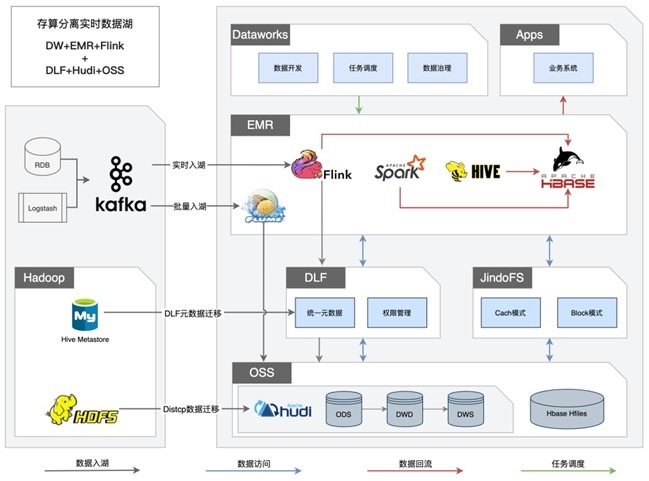
互联网金融公司湖与仓的融合,湖仓一体
· 业务难点
· 公司的第一代数据湖是基于 Hadoop + OSS 搭建的,同时引入的数据中台的执行引擎和存储是 Maxcompute,两套异构的执行引擎带来存储冗余、元数据不统一、权限不统一、湖仓计算不能自由流动
· 解决方案
· 如图架构 MaxCompute 和 EMR 不同引擎用于不同的业务场景,使用阿里云数据湖构建 DLF 统一做元数据管理和统一用户权限管理。通过 DataWorks 进行全链路数据治理,提升数据质量与应用能力
· 业务价值
· 将 EMR 的元数据统一到DLF,底层使用 OSS 作统一存储,并通过湖仓一体打通EMR数据湖和 MaxCompute 数仓两套体系,让数据和计算在湖和仓之间自由流动
· 实现湖仓数据分层存储。数据中台对数据湖数据进行维度建模的中间表存储在 MaxCompute上,EMR 或其他引擎消费 ADS 层
更多关于数据湖方案及技术的解析,请参考我们后续文章。
想要了解更多资讯,欢迎关注我们的微信公众号:数据湖技术圈。
来源:业界供稿
好文章,需要你的鼓励


星际之门AI数据中心建设雄心遭遇现实挑战
2025年1月,OpenAI、软银、甲骨文和MGX联合宣布"星际之门"计划,承诺投资5000亿美元,部署高达10GW算力基础设施。如今,该项目已从白宫发布会上的宏大承诺,演变为一场前所未有规模的基础设施建设实验。项目已扩展至德克萨斯、威斯康星、俄亥俄等多地,并延伸至阿布扎比和挪威。然而,融资争议、合作伙伴摩擦、能源压力及政策监管收紧,正考验着这一"AI工业园"模式能否真正落地。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

OKX推出AI智能体招聘与支付市场平台
加密货币交易所OKX正式推出AI智能体交易市场OKX AI,允许AI代理相互雇佣、自主结算,并建立基于区块链的可携带信誉档案。该平台经过50家早期服务商封测后向开发者开放,依托稳定币和链上支付基础设施,支持全天候微支付。OKX创始人徐明星表示,传统金融基础设施为人类而建,智能体经济需要为自主软件专门设计的基础设施。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2022
06/02
15:20
分享
点赞

星际之门AI数据中心建设雄心遭遇现实挑战
OKX推出AI智能体招聘与支付市场平台
AI编程Token成本将与开发者薪资持平,企业如何应对?
机器学习项目全生命周期管理的成功实践
SVT Robotics的Softbot平台交易量突破40亿笔
Agibot第15000台人形机器人下线,具身AI量产加速
杜尔为大众汽车建设跨工厂集成CO?高效涂装车间
AI对就业的影响:大规模裁员背后的真相与数据
AI重复申请问题推动电网转向"承诺优先"规划
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
