
数据湖架构及概念简介
——陈鑫伟
阿里云开源大数据技术专家

数据湖概念于 2010 年提出,其目的是解决传统数据仓库和数据集所面临的两个问题:其一,希望通过统一的元数据存储解决数据集之间的数据孤岛问题;其二,希望存储原始数据,而非存储数据集建设过程中经过裁剪后的数据,以避免数据原始信息的丢失。当时,开源的 Hadoop 是数据湖的主要代表。
随着云计算的发展, 2015 年,各个云厂商开始围绕云上的对象存储重新解读和推广数据库。云上对象存储具有大规模、高可用和低成本的优势,逐步替代了HDFS成为云上统一存储的主流选择。云上的对象存储支持结构化、半结构化和非结构化的数据类型,同时以存算分离的架构和更开放的数据访问方式支持多种计算引擎的分析,主要代表有 AWS S3 和阿里云的OSS。
2019 年,随着 databricks 公司和 uber 公司陆续推出datalake、Hudi 和iceberg 数据湖格式,通过在数据湖的原始数据之上再构建一层元数据层、索引层的方式,解决数据湖上数据的可靠性、一致性和性能等问题。同时, Flink 流式计算的技术、AI 技术等也开始在数据湖上有了更广泛的应用。
同年,AWS和阿里云也相继推出了Data Lake Formation等数据库管理和构建的产品,能够帮助用户更快速地构建和管理云上数据库。数据湖架构的不断演进和成熟也得到了更多客户的关注和选择。
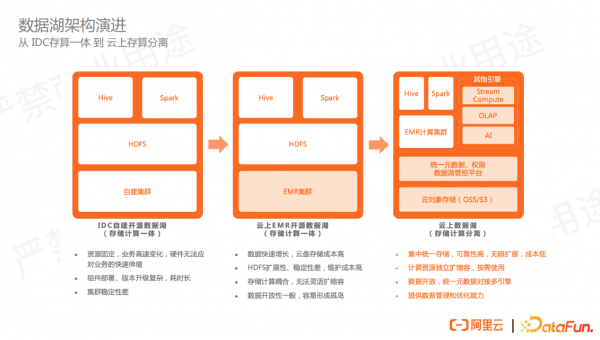
早期,用户基本往往在IDC机房里基于服务器或虚拟机建设 hadoop 集群,主要的存储为 HDFS ,主流的计算引擎为 Hive 和 Spark 等。。
随着云计算的发展,很多用户为了解决 IDC 机房在资源扩缩容和运维方面的困难,开始选择在云上构建自己的数据库平台。可以选择云上提供的大数据构建平台,比如EMR云产品帮助快速建设和部署多个集群。
但大部分早期用户选择直接将云下的架构搬到云上,依然以 HDFS 为主要的存储,因此 HDFS 的问题依然存在,比如 namenode 的扩展性问题、稳定性问题,比如计算资源和存储资源的耦合问题等。数据也存储于集群内部,跨集群、跨引擎的数据访问也会存在问题。
而现在更主流的选择是数据湖架构,基于云上的OSS或云上对象存储做统一存储。在存储之上,有一套管控平台进行统一的元数据管理、权限管理、数据的治理。再上层会对接更丰富的计算引擎或计算产品,除了hadoop、Hive、Spark 等离线分析引擎,也可以对接流式的引擎比如Flink。
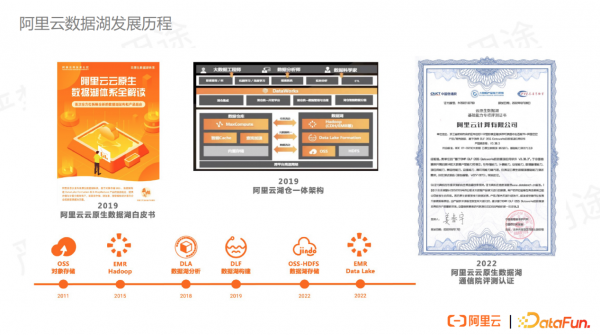
阿里云在数据湖方向已经经过了很多年的发展。最早期的 OSS 发布于2011 年,彼时数据湖的应用场景还很少。直到 2015 年,阿里云发布了云上 EMR hadoop 产品,开始将 Hive 和 Spark 放至 EMR 集群,再将数据放至OSS,存算分离的架构开始流行。
2018 年和 2019 年,阿里云相继推出了数据湖分析和数据湖构建两款专门面向数据湖的产品。 2022 年推出了的数据湖存储(OSS-HDFS)以及EMR Data Lake专有集群,数据湖解决方案的产品矩阵逐步形成。
2019 年,阿里云发布了《阿里云云原生数据湖白皮书》,很多业内伙伴都基于这份白皮书开始研究学习和建设自己的数据湖;同年阿里云也打通数据湖和自研的MaxCompute云原生数仓,推出了湖仓一体架构。 2022 年,阿里云成为首批通过通信院的云原生数据湖测评认证的企业。
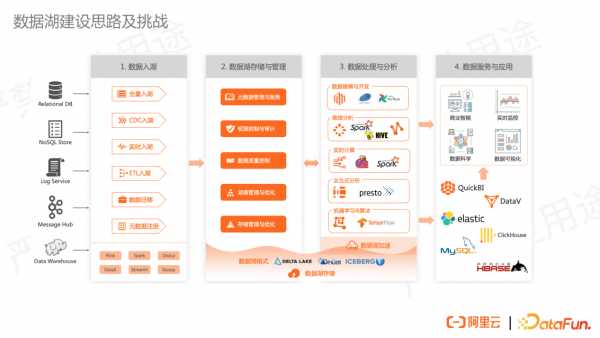
经过多年在数据湖的方向上,阿里云在数据湖的建设上也积累了一定的经验和思路。我们认为数据湖的建设主要包括四个阶段。
第一阶段:数据入湖。通过各种各样的入湖方式将数据导入数据库。入库方式可以根据自己的业务需求和场景进行选择,比如全量入库、cdc 更新入库、实时追加写入以及整个 Hadoop 集群搬迁上云等。
第二阶段:数据湖存储与管理,以帮助用户更好地管理发现和高效使用数据库里的数据。此阶段主要包括以下几个方面:
- 统一的数据目录:一方面能够提供元数据的服务,另一方面能够提供数据的快速检索能力。
- 权限控制与审计:因为数据湖本身是相对开放和松散的体系,需要有比较强的权限管控的能力来保证企业数据的安全性。
- 数据质量控制:这也是避免数据湖发展成数据沼泽的关键手段。
- 湖表管理与优化:数据湖的格式也会有较多优化和管理的需求。
- 存储管理与优化:对象存储提供了数据冷热分层的特性,但这些特性使用不够方便,因此也需要有自动化的手段来解决。
第三阶段:数据处理与分析。可以根据实际场景选择多种数据处理和分析方式,比如做离线分析、实时计算、交互式分析、AI 的训练等。
第四阶段:数据服务与应用。数据湖较为开放,因此可以直接用 BI 系统、可视化系统连接数据湖上的引擎,直接进行实时分析或可视化的数据展示等。另一方面,数据库里的数据也可以再进一步同步或 Sync 到更专业的数据系统中,比如到 ES 里进行下一步数据检索,比如到 Clickhouse/StarRocks做更丰富的多元分析等。
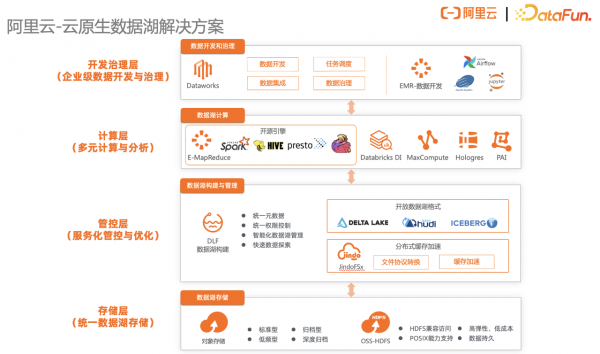
经历了多年的摸索后,阿里云推出了一个较为完整的云原生数据湖解决方案,整体架构如上图所示。
底层是统一的存储层,并对外提供文件访问的接口和协议。
第二层是管控层,可以理解为服务化的管控与优化,一方面提供统一的元数据、统一权限等面向引擎的管控能力,另一方面提供元数据检索、数据指标、血缘等面向用户的数据管理能力,同时支持文件合并、数据生命周期管理、索引统计信息的加速等面向湖内数据和上层引擎的优化能力。
第三层是多元的计算与分析层,可以通开源或阿里自研的很多分析引擎对湖内数据进行加工和处理。
最上层是数据开发层,提供了面向湖和仓完善的数据开发体系以及数据治理的平台。
由此可见,数据湖的建设不仅仅是大数据相关技术的集成和应用,同时也是一个复杂的系统工程,需要有成熟的方法论以及平台型的基础设施做支撑,才能建设出安全可靠、功能完善、成本可控的企业级数据湖。
来源:业界供稿
好文章,需要你的鼓励


CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
很多人担心被AI取代,陷入无意义感。按照杨元庆的思路,其实无论是模型的打造者,还是模型的使用者,都不该把AI放在人的对立面。

MIT递归语言模型:突破AI上下文限制的新方法
MIT研究团队提出递归语言模型(RLM),通过将长文本存储在外部编程环境中,让AI能够编写代码来探索和分解文本,并递归调用自身处理子任务。该方法成功处理了比传统模型大两个数量级的文本长度,在多项长文本任务上显著优于现有方法,同时保持了相当的成本效率,为AI处理超长文本提供了全新解决方案。

Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
谷歌宣布对Gmail进行重大升级,全面集成Gemini AI功能,将其转变为"个人主动式收件箱助手"。新功能包括AI收件箱视图,可按优先级自动分组邮件;"帮我快速了解"功能提供邮件活动摘要;扩展"帮我写邮件"工具至所有用户;支持复杂问题查询如"我的航班何时降落"。部分功能免费提供,高级功能需付费订阅。谷歌强调用户数据安全,邮件内容不会用于训练公共AI模型。

华为研究团队突破代码修复瓶颈,8B模型击败32B巨型对手!
华为研究团队推出SWE-Lego框架,通过混合数据集、改进监督学习和测试时扩展三大创新,让8B参数AI模型在代码自动修复任务上击败32B对手。该系统在SWE-bench Verified测试中达到42.2%成功率,加上扩展技术后提升至49.6%,证明了精巧方法设计胜过简单规模扩展的技术理念。
2022
09/01
10:03
分享
点赞

联想集团混合式AI实践获权威肯定,CES期间获评“全球科技引领企业”
CES上杨元庆首谈AGI,碾压人类的叙事不会让AI更聪明
CES 2026 | 重大更新:NVIDIA DGX Spark开启“云边端”模式
Gmail新增Gemini驱动AI功能,智能优先级和摘要来袭
研究发现商业AI模型可完整还原《哈利·波特》原著内容
Razer在2026年CES展会推出全息AI伴侣项目
CES 2026:英伟达新架构亮相,AMD发布新芯片,Razer推出AI奇异产品
通过舞蹈认识LimX Dynamics的人形机器人Oli
谷歌为Gmail搜索引入AI概览功能并推出实验性AI智能收件箱
DuRoBo Krono:搭载AI助手的智能手机尺寸电子阅读器
OpenAI推出ChatGPT Health医疗问答功能
Anthropic寻求3500亿美元估值融资100亿美元
