
EMRжиАѕЗЂВМжЧФмдЫЮЌеяЖЯЯЕЭГ(EMR Doctor)ЁЊЁЊПЊдДДѓЪ§ОнЦНЬЈ
ДѓЪ§ОндЫЮЌЕФЬєеН—ШчКЮБЃжЄМЏШКЮШЖЈгыдЫаааЇТЪ
ЦѓвЕМЖДѓЪ§ОнМЏШКЭЈГЃгЕгаКЃСПЕФЪ§ОнДцДЂЁЂШеГЃдЫЫуГЩИЩЩЯЭђЕФМЦЫуШЮЮёЃЌашвЊТњзуИїРрЩЯВувЕЮёЕФМЦЫуашЧѓЁЃЖдгкетРрМЏШКЕФдЫЮЌЭљЭљГфТњзХЬєеНЃККЃСПЕФЪ§ОнЁЂХгдгЕФзщМўвдМАзщМўжЎМфИДдгЕФвРРЕЙиЯЕЁЂЖдгкЪБаЇвЊЧѓЕФЕФдЫЫуШЮЮёЃЌЖМЛсЬсЩ§дЫЮЌФбЖШЁЃзїЮЊжЇГХЦНЬЈЃЌДѓЪ§ОнМЏШКЕФЮШЖЈадКЭдЫаааЇТЪЃЌЛсжБНггАЯьЕНЙЋЫОвЕЮёЕФе§ГЃдЫзїКЭЗЂеЙЁЃ
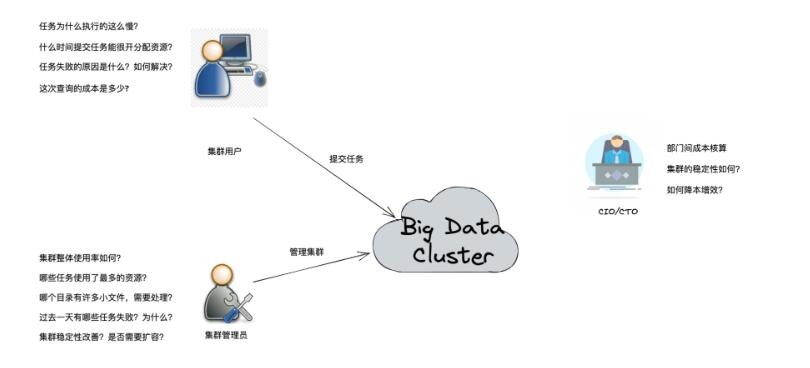
МЏШКЙмРэдБЭљЭљЖдећЬхМЏШКзіКУСЫМрПидЫЮЌЬхЯЕЃЌЖдгкДѓЪ§ОнМЏШКЃЌМђЕЅЕФМрПидЫЮЌЬхЯЕФмЙЛАяжњЙмРэдБдкгіЕНЙЪеЯЕФЪБКђЖЈЮЛЮЪЬтЁЃЕЋЖдгкећЬхМЏШКЕФдЫаааЇТЪЃЌМЏШКЕФзДЬЌЃЌЭЈЙ§ЕЅДПЕФМрПижИБъКмФбИјГівЛИіШЋУцЕФНтД№ЁЃ
ЖдгкДѓЪ§ОнМЏШКЃЌЙмРэдБвдМА CIO ЕШИќЙизЂвдЯТЕФФкШнЃК
Ёё МЏШКФкЕФНкЕуЕФдЫаазДЬЌКЭзЪдДЪЙгУзДПіЃЛ
Ёё дЫаадкМЏШКЩЯЕФЗўЮёзщМўЕФзДЬЌМрПиКЭвьГЃДІРэЃЌАќРЈ YARNЁЂHDFSЁЂHive КЭ Spark ЕШЃЛ
Ёё МЦЫуШЮЮёдЫааЧщПіКЭжДаааЇТЪЃЛ
Ёё ећЬхМЏШКЕФНЁПЕГЬЖШКЭШчКЮИФНјЁЃ
УцЖддЫЮЌЬєеНЃЌEMRжиАѕЭЦГіЃКжЧФмдЫЮЌеяЖЯЯЕЭГ(EMR Doctor)
ЮЊСЫЬсЩ§ДѓЪ§ОнМЏШКдЫЮЌаЇТЪЃЌИЈжњ EMR гУЛЇЭъЩЦМЏШКМрПиЬхЯЕЁЃE-MapReduce ЭЦГіУцЯђПЊдДДѓЪ§ОнМЏШКЕФжЧФмдЫЮЌеяЖЯЯЕЭГ E-MapReduce DoctorЃЈМђГЦEMR DoctorЃЉЁЃ EMR Doctor зїЮЊПЊдДДѓЪ§ОнМЏШКЕФЙмМвЃЌЛсздЖЏУПШебВМьМЏШКЁЃМЏШКЙмРэдБжЛашвЊЖЈЦкВщПДНЁПЕМьВщБЈИцЃЌВЂЧвИљОнБЈИцжаЕФНЈвщЖдМЏШКзіЯргІЕФгХЛЏЕїећЃЌМДПЩШЋОжСЫНтМЏШКЕФНЁПЕзДПіКЭЖЏЬЌзпЪЦЃЌВЂБЃГжМЏШКЕФНЁПЕЖШЁЃ
ШчКЮЪЙгУ EMR Doctor
1. НјШы EMR ПижЦЬЈНЁПЕМьВщвГУцЁЃ
l ЕЧТМ EMR on ECS ПижЦЬЈЁЃ
l дкЖЅВПВЫЕЅРИДІЃЌИљОнЪЕМЪЧщПібЁдёЕигђКЭзЪдДзщЁЃ
l дкМЏШКЙмРэвГУцЃЌЕЅЛїФПБъМЏШКЕФМЏШКIDЁЃ
l ЕЅЛїЩЯЗНЕФНЁПЕМьВщвГЧЉЁЃ
2. дкНЁПЕМьВщвГУцЃЌФњПЩвдПДЕНЕБЧАМЏШКЕФНЁПЕМьВщБЈИцЃЈT+1ЃЉЁЃНЁПЕзДЬЌСаЯдЪОСЫИУМЏШКЕФНЁПЕЖШЃЌФњПЩвдЕуЛїВщПДБЈИцНјШыМьВщБЈИцвГУцЁЃ
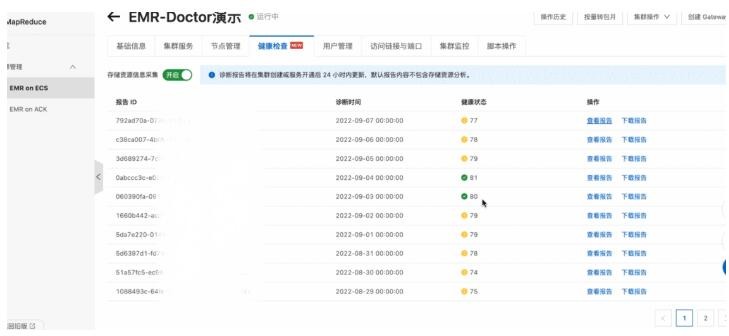
3. НЁПЕМьВщБЈИцжаАќКЌМЏШКМЦЫузЪдДЕФзмЬхЗжЮі

4. НЁПЕМьВщБЈИцжаАќКЌМЦЫуШЮЮёДгИїИіЮЌЖШЕФХХУћВЂИјГіШЮЮёЕїгХНЈвщ

5. НЁПЕМьВщБЈИцжаАќКЌЖдМЏШКДцДЂЕФзмЬхЗжЮіЃЌвдМАДѓаЁЮФМўКЭРфШШЪ§ОнЕФЯъЯИЗжЮі
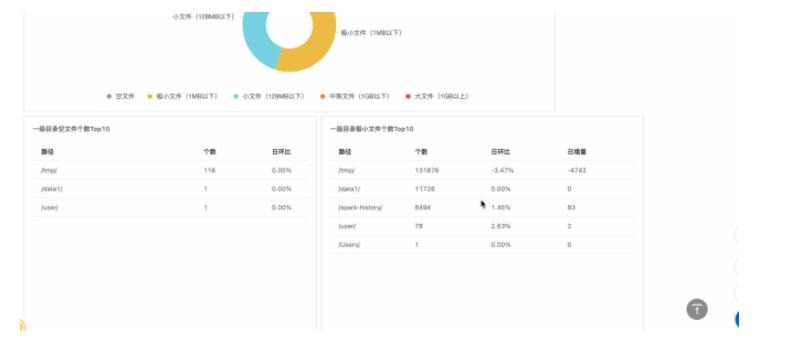
6. НЁПЕМьВщБЈИцжївЊЗжЮіФкШнШчЯТЃЌИќЯъЯИЫЕУїЧыВЮМћВщПДНЁПЕМьВщзДЬЌКЭБЈИц
| МЦЫузЪдДЗжЮі | ИХЪі | зДЬЌИХЪі |
| ашвЊЙизЂЕФЮЪЬт | ||
| МЦЫуЛљДЁаХЯЂ | МЏШКМЦЫуЦРЗж | |
| МЏШКЫуСІФкДцЪБ | ||
| МЏШКЫуСІCPUЪБ | ||
| МЦЫув§ЧцФкДцЫуСІЪБ | ||
| МЦЫуШЮЮёаХЯЂ | МЦЫуШЮЮёЫуСІФкДцЪБЗжЮі | |
| МЦЫуШЮЮёЦРЗжХХааАё | ||
| Spark | SparkШЮЮёЫуСІЗжЮіМАЕїгХНЈвщ | |
| Tez | TezШЮЮёЫуСІЗжЮіМАЕїгХНЈвщ | |
| MapReduce | MapReduceШЮЮёЫуСІЗжЮіМАЕїгХНЈвщ | |
| HDFSДцДЂзЪдДЗжЮі ЃЈашПЊЦєДцДЂзЪдДаХЯЂВЩМЏПЊЙиЃЉ |
ИХЪі | зДЬЌИХЪі |
| ашвЊЙизЂЕФЮЪЬт | ||
| HDFSЛљДЁаХЯЂ | HDFSДцДЂзЪдДЪЙгУЧїЪЦ | |
| ЮФМўзмЪ§ЫцЪБМфБфЛЏЧїЪЦ | ||
| ЦРЗжЧїЪЦ | ||
| HDFSЮФМўДѓаЁЗжВМ | HDFSЮФМўДѓаЁБШР§ | |
| вЛМЖФПТМПеЮФМўИіЪ§Top10 | ||
| вЛМЖФПТММЋаЁЮФМўИіЪ§Top10 | ||
| вЛМЖФПТМаЁЮФМўИіЪ§Top10 | ||
| вЛМЖФПТМжаЕШЮФМўИіЪ§Top10 | ||
| вЛМЖФПТМДѓЮФМўИіЪ§Top10 | ||
| HDFSРфШШЪ§ОнЗжВМ | HDFSРфШШЪ§Он | |
| вЛМЖФПТММЋРфЪ§ОнДѓаЁTop10 | ||
| вЛМЖФПТМРфЪ§ОнДѓаЁTop10 | ||
| вЛМЖФПТМЮТЪ§ОнДѓаЁTop10 | ||
| вЛМЖФПТМШШЪ§ОнДѓаЁTop10 | ||
| HIVEДцДЂзЪдДЗжЮі ЃЈашПЊЦєДцДЂзЪдДаХЯЂВЩМЏПЊЙиЃЉ |
ИХЪі | зДЬЌИХЪі |
| ашвЊЙизЂЕФЮЪЬт | ||
| HiveЛљДЁаХЯЂ | ДцДЂЧїЪЦ | |
| ЮФМўЪ§СПЧїЪЦ | ||
| ЦРЗжЧїЪЦ | ||
| HiveПтаХЯЂ | ПтДцДЂХХУћ | |
| ПтЮФМўзмЪ§ХХУћ | ||
| ПтЦРЗж | ||
| HiveБэЮФМўДѓаЁЗжВМ | HiveБэЮФМўДѓаЁЗжВМБШР§ | |
| HiveБэПеЮФМўИіЪ§Top10 | ||
| HiveБэМЋаЁЮФМўИіЪ§Top10 | ||
| HiveБэаЁЮФМўИіЪ§Top10 | ||
| HiveжаЕШЮФМўИіЪ§Top10 | ||
| HiveДѓЮФМўИіЪ§Top10 | ||
| HiveРфШШЪ§ОнЗжВМ | HiveРфШШЪ§ОнЗжВМ | |
| HiveБэМЋРфЪ§ОнДѓаЁTop10 |
РДдДЃКвЕНчЙЉИх
КУЮФеТЃЌашвЊФуЕФЙФРј


ДѓжкЦћГЕЭЦНјЦНМлЕчЖЏГЕеНТдЃЌСНПюаТГЕТЪЯШЯТЯп
ДѓжкЦћГЕЦьЯТID. PoloгыCupra RavalвбдкЮїАрбРТэЭаРзЖћЙЄГЇе§ЪНЯТЯпЭЖВњЁЃСНПюГЕаЭЦ№ЪлМлЗжБ№ЮЊ24,995ХЗдЊКЭ26,000ХЗдЊЃЌОљЛљгкMEB+ЦНЬЈДђдьЃЌДюди37kWhЛђ52kWhЕчГизщЃЌајКНРяГЬзюИпПЩДя454ЙЋРяЁЃетЪЧДѓжк"ЕчЖЏГЧЪаГЕМвзх"ЯЕСаЕФЪзХњВњЦЗЃЌдЄМЦНёФъЯФФЉЧяГѕПЊЪМНЛИЖЁЃДѓжкМЏЭХЭЈЙ§ПчЦЗХЦзЪдДећКЯЃЌЪЕЯждМ6вкХЗдЊЕФГЩБОНкдМЃЌКѓајЛЙНЋЭЦГіID. CrossЕШаТГЩдБЁЃ

ЕБAIЛњЦїШЫЁАздаХЕиЁАзВЯђЧНБкЃКSTATE16баОПдКНвЪОЮяРэAIЯЕЭГжаФЧаЉЮоЩљЮоЯЂЕФжТУќДэЮѓ
STATE16баОПдКетЦЊзлЪіЗЂЯжЃЌЮяРэAIЯЕЭГДцдк"ОВФЌЪЇаЇ"ЗчЯеЁЊЁЊAIвдИпЖШздаХжДааЛљгкДэЮѓЪРНчаХЯЂЕФЖЏзїЃЌШДВЛДЅЗЂШЮКЮБЈОЏЃЌВЂЬсГідкAIЪфГігыЮяРэжДаажЎМфНЈСЂЖРСЂЪкШЈВуЕФПђМмЁЃ

Ш§аЧHealthгІгУгРДAIЩ§МЖЃЌGalaxy Watch 9ЗЂВМЧАЯІИќаТЬсЧАНвЯў
Ш§аЧаћВМНЋгк6дТ8ШеЦ№ЮЊSamsung HealthгІгУЭЦГіжиАѕЙІФмИќаТЃЌИЯдкGalaxy Watch 9ДЋЮХЗЂВМжЎЧАТфЕиЁЃаТАцБОНЋв§ШыЖрЯюAIЧ§ЖЏЕФЩњЮяЬиеїЗжЮіЙІФмЃЌАќРЈЃКзлКЯаФТЪЁЂбЊбѕЁЂЦЄЗєЮТЖШЕШЪ§ОнЕФУПШеЛюСІЦРЗжЃЈVitalsЃЉЁЂНсКЯЬхГЩЗжЪ§ОнЦРЙРГЄЦкаФдрНЁПЕЕФаФдрНЁПЕЦРЗжЁЂгХЛЏбЕСЗЧПЖШЕФУПШегабѕИККЩзЗзйЃЌвдМАКсЯђЖдБШгУЛЇШКЬхЕФНЁЩэжИЪ§ЁЃДЫЭтЃЌгІгУНчУцНЋжиаТЛЎЗжЮЊЫЏУпЁЂгЊбјЁЂЛюЖЏЁЂе§ФюКЭЬхеїЮхДѓАхПщЃЌВЂаТдіПЙбѕЛЏжИЪ§ЁЂФъСфжИЪ§КЭЬ§СІБЃЛЄЕШИіадЛЏЙІФмЁЃ

ЕБAIбЇЛсЁАБпИЩБпбЇЁАЃКUIUCгыЮЂШэСЊКЯДђдьЕФЭјвГжЧФмЬхбЕСЗаТЗЖЪН
UIUCгыЮЂШэСЊКЯбаЗЂЕФOpenWebRLПђМмШУ4BаЁФЃаЭНіЦО400ЬѕГѕЪМЪ§ОнЃЌЭЈЙ§дкецЪЕЭјеОЩЯБпзіБпбЇЕФЧПЛЏбЇЯАЗНЪНЃЌдкЭјвГжЧФмЬхЛљзМЩЯГЌдНСЫгУ27ЭђЬѕЪ§ОнбЕСЗЕФОКељЖдЪжЁЃ
2022
09/20
12:07
ЗжЯэ
Еудо

Ш§аЧHealthгІгУгРДAIЩ§МЖЃЌGalaxy Watch 9ЗЂВМЧАЯІИќаТЬсЧАНвЯў
MetaжЧФмблОЕБЛЦиКЌ"ШЫСГЪЖБ№"зЗзйДњТыЃЌвўЫНЗчЯев§ЗЂОЏЪО
GeminiЦѓвЕжЧФмЬхЦНЬЈЕФжЧФмЬхRAGШчКЮЪЕЯжПЩППЯьгІ
ТщЪЁРэЙЄбЇдКAIгыМЦЫубаЬжЛсЃКММЪѕНјВНжаВЛПЩЛђШБЕФШЫЮФвђЫи
бЧТэбЗШЋаТЪ§ОнжааФТЗгЩМмЙЙНЕЕЭAWSЭјТчФмКФ40%
iOS 27МДНЋЗЂВМЃЌЖрПюiPhoneгІгУНЋгРДШЋаТЩшМЦЩ§МЖ
СЌНгадвбГЩЮЊгыМЦЫуКЭДцДЂЭЌЕШживЊЕФAIЛљДЁЩшЪЉКЫаФвЊЫи
ПЊЗЂепШддкЕШД§MetaзюаТAIФЃаЭЕФAPIЗУЮЪШЈЯо
ТѕЯђTokenОМУЪБДњЃЌF5вдЁАAIИГФмНЛИЖЁБжўЛљжЧФмаТЩњЬЌ
УзРЁЄФТРЬсжиЗЕЙЋжкЪгвАЃЌНїЩїЗЂЩљ
ЬиЫЙРвЩЫЦЩОГ§FSDжЄОнЃЌПЈЬиБЫРеМгЫйЕчЖЏЛЏВМОжЃЌИпбЙЯЕЭГММЪѕХрбЕПЬВЛШнЛК
жЧФмЬхЭјТчСїСПЪзГЌецШЫЗУЮЪЃЌ"ЫРЭіЛЅСЊЭј"РэТлв§ЗЂаТељвщ
