
众筹上线10h完成率高达1143%,清听声学屏幕定向音箱到底是什么?
3月23日,美国东部时间11点(北京时间3月23日23点),清听声学聚音屏Focusound Screen ®全透明屏幕定向发声音箱正式在美国Kickstarter开放众筹。根据ks众筹页面数据显示,这款定向音箱目前已有143名支持者,上线1小时已达成目标金额,10小时众筹完成率高达1143%,远超预期的众筹目标(数据截止发稿前)。
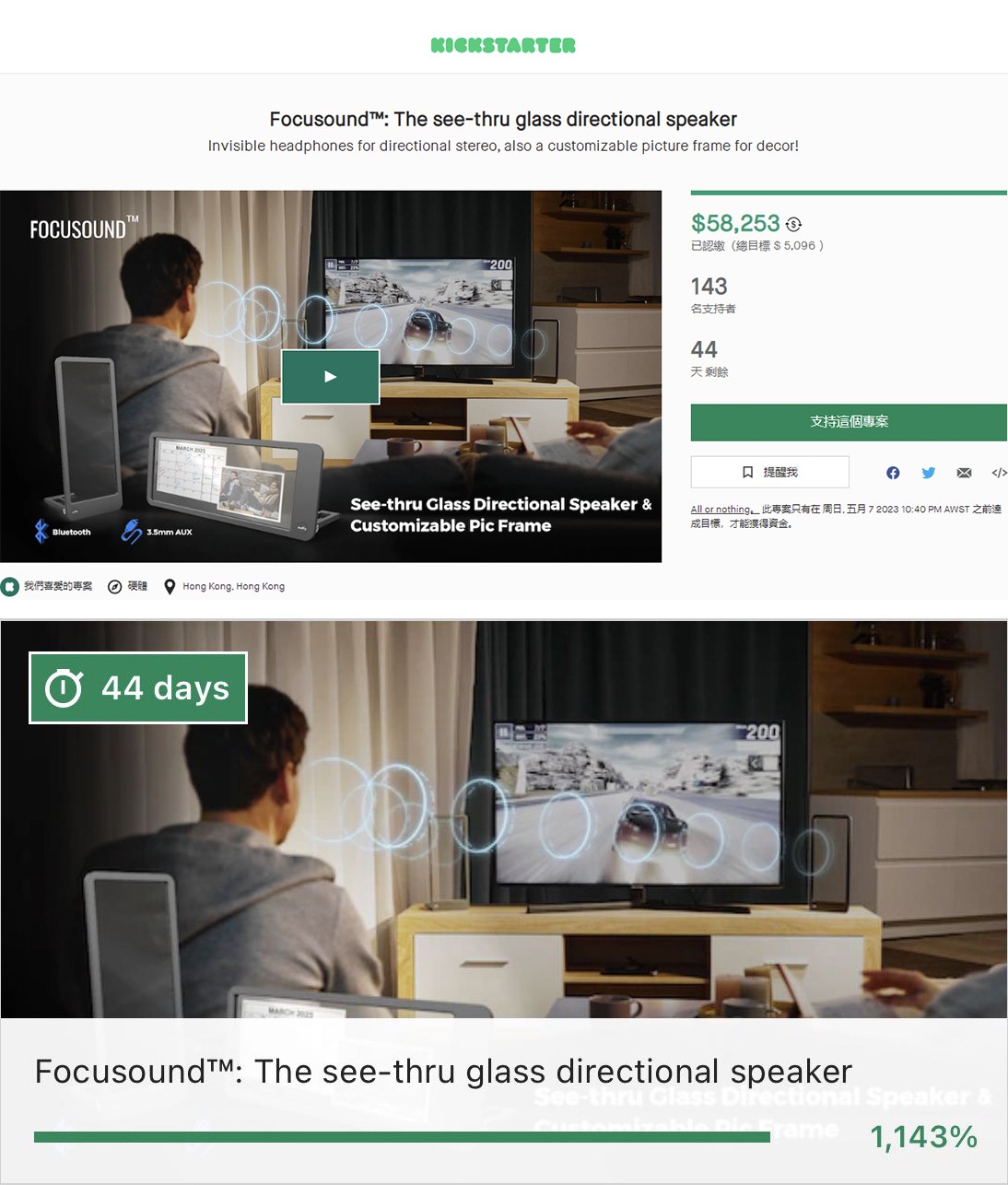
那么,这款屏幕定向发声技术“黑科技”新品聚音屏会给我们的生活带来怎样的惊喜呢?我们一起来看。
01
以创新声学驱动 直击消费者听音痛点
5G时代,万物互联,在声学与智能交互的时代浪潮下,消费者对音频产品的期望越来越高。
在智能音频高歌猛进的增长趋势背后,是用户需求的不断增长变化,高质量音效、健康护耳、私密听音等等。
如何在深夜享受激情澎湃的世界杯,还不影响家人睡觉?后疫情时代,如何与爱人同时居家办公、视讯会议还互不干扰?如何让年迈的父母也能享受水晶般的听音体验?如何在家里开启沉浸式电竞,还不影响家人休息?
基于此,为了满足消费者对听音频产品的多种使用场景,快速高效解决日常生活痛点,清听声学自主研发屏幕定向发声技术,让用户不戴耳机即可实现私密听音。

02
全球独家专利技术 私域声场澎湃音效
聚音屏是清听声学全球创新研发的屏幕定向发声技术产品,无需借助传统扬声器,通过新材料、新工艺,辅助核心专利算法,直接使用屏幕作为发声单元,实现屏幕定向发声,为用户带来更加大胆的听音探索和沉浸式的创新听音体验,在提升整体个性化声音隐私性的同时,实现科技赋能新声态。利用屏幕本身作为发声单元,高语音清晰度,营造超越整个屏幕的全域音效,实现“音画融合”,提供360°全环绕沉浸式音效体验。

03
秉承科技生活美学 用匠心质造不凡
清听声学全透明屏幕定向发声音箱聚音屏Focusound Screen®采用一体化精密工艺制程,精心打造细节质感。整体设计概念化繁为简,使用低调沉稳的科技黑为主色调,营造出流畅优美的弧面,完美平衡了美学设计与科技格调。产品自带灵活旋钮,横向90°灵动旋转,180°自由翻转,随性调节角度;机身仅相当于一部手机的重量,轻巧易携。作为科技家居产品,日常也可以作为便签夹或装饰摆台,适合多场景使用。

清听声学在定向发声技术领域拥有先导性创新优势,率先在国内完成定向发声技术产品化、商业化,是聚音屏 Focusound Screen ®的发明者及全球专利所有者,目前在包含中国、美国、日本、德国、法国、英国等国家拥有250多项核心技术专利。未来,清听声学将持续在声学+显示行业持续精准发力,深耕细作,聚力创新,以科技实力赋能产业化创新升级。
据悉,此次众筹时间一直持续到5月初,预计今年6月底,国内消费者也将拥有这款屏幕定向发声技术新品聚音屏Focusound Screen ®。期间,清听声学将陆续推出用户体验活动,还有机会免费获得同款聚音屏(具体参与信息以官方平台公布为准),感兴趣的用户,可提前关注众筹动态,提前解锁黑科技!
来源:业界供稿
好文章,需要你的鼓励


奥运级别的努力:首席信息官为2026年AI颠覆做准备
AI颠覆预计将在2026年持续,推动企业适应不断演进的技术并扩大规模。国际奥委会、Moderna和Sportradar的领导者在纽约路透社峰会上分享了他们的AI策略。讨论焦点包括自建AI与购买第三方资源的选择,AI在内部流程优化和外部产品开发中的应用,以及小型模型在日常应用中的潜力。专家建议,企业应将AI建设融入企业文化,以创新而非成本节约为驱动力。

字节跳动发布GAR:让AI能像人类一样精准理解图像任何区域的突破性技术
字节跳动等机构联合发布GAR技术,让AI能同时理解图像的全局和局部信息,实现对多个区域间复杂关系的准确分析。该技术通过RoI对齐特征重放方法,在保持全局视野的同时提取精确细节,在多项测试中表现出色,甚至在某些指标上超越了体积更大的模型,为AI视觉理解能力带来重要突破。

Spotify推出AI播放列表功能让用户掌控推荐算法
Spotify在新西兰测试推出AI提示播放列表功能,用户可通过文字描述需求让AI根据指令和听歌历史生成个性化播放列表。该功能允许用户设置定期刷新,相当于创建可控制算法的每周发现播放列表。这是Spotify赋予用户更多控制权努力的一部分,此前其AI DJ功能也增加了语音提示选项,反映了各平台让用户更好控制算法推荐的趋势。

Inclusion AI推出万亿参数思维模型Ring-1T:首个开源的超大规模推理引擎如何重塑AI思考边界
Inclusion AI团队推出首个开源万亿参数思维模型Ring-1T,通过IcePop、C3PO++和ASystem三项核心技术突破,解决了超大规模强化学习训练的稳定性和效率难题。该模型在AIME-2025获得93.4分,IMO-2025达到银牌水平,CodeForces获得2088分,展现出卓越的数学推理和编程能力,为AI推理能力发展树立了新的里程碑。
2023
03/24
14:29
分享
点赞

为AI+而生,海辰储能发布全球首款锂钠协同AIDC全时长储能解决方案
长时储能开启智慧未来:海辰储能生态日全球首发三大新品
Arm 借助融合型 AI 数据中心,重塑计算格局
奥运级别的努力:首席信息官为2026年AI颠覆做准备
Spotify推出AI播放列表功能让用户掌控推荐算法
Adobe押注生成式AI获得回报,年度营收创历史新高
OpenAI与迪士尼达成十亿美元合作协议,米老鼠和漫威角色进入Sora
甲骨文150亿美元数据中心投资导致股价下跌
Spoor鸟类监测AI软件需求飞速增长
制药行业AI数据质量危机:垃圾进垃圾出的隐患
Harness获得2.4亿美元融资,估值达55亿美元,专注自动化AI编码后的开发流程
英伟达CEO黄仁勋独家专访:万亿美元押注AI工厂将成为新时代计算机
