
随心组合,拓展智慧办公新形态,联想TIO Flex新品发布
近日,联想ThinkCentre M家族新一代产品ThinkCentre TIO Flex重磅发布。该产品继续采用TIO模块化的理念,将显示器与Tiny(小Q)主机通过底座连接的方式合二为一,使其具备广泛且灵活的兼容性和扩展能力,满足不同行业客户的细分需求。
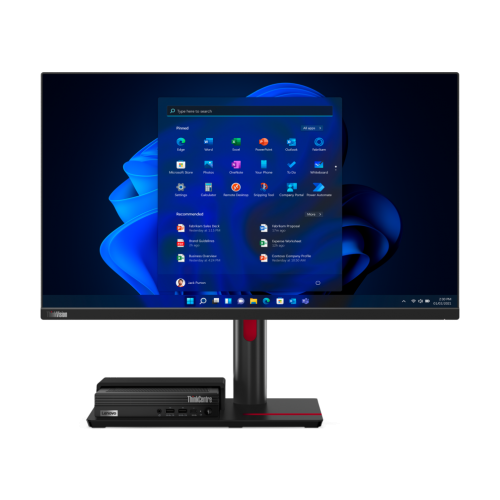
“三个灵活”设计,一机多能
ThinkCentre TIO Flex是一款坚持实用主义思维所打造的产品,它打破了传统分体式台式机和一体机的界限,兼具了分体PC的高性能、灵活扩展、易于维护的特性以及一体机产品简洁美观、占用空间小的特性,方便企业IT资产的管理维护和升级。
•灵活的Tiny主机支持
在组合模式上,TIO Flex兼容目前所有在售的Tiny主机,并尽可能做到让用户能够“零学习成本”完成组装和上手。
TIO Flex通过支架卡槽的方式将显示器与Tiny主机相连接,显示器底座集成了一体式主机的连接端口,用户仅需将Tiny主机轻轻推进卡槽即可一步完成安装;显示器立柱采用隐藏式连线设计,配合随机附赠的连线器轻松完成线缆收纳;用户按下Tiny主机电源键,即可实现台式机和显示器同步开机运行。
•灵活的显示器选择
ThinkCentre TIO Flex通过创新的卡槽模块分别兼容不同尺寸、不同规格甚至不同品牌的显示器,简而言之,只要是购买过或计划购买Tiny主机的用户均可以通过TIO Flex的模块化组合方式实现二合一的效果。
ThinkCentre TIO Flex拥有一个灵活的支架模块,支持21.5-27英寸的多种显示器,能够实现俯仰-5°~23°调节,上下80~130mm的移动。此外用户还可以通过选配VESA转换支架来安装第三方显示器。
•灵活的采购方式
两种灵活的采购模式,支持单独选件采购,也支持统一包装发货,使TIO Flex具备超长的产品生命周期。
用户可以根据自身需要,单独购买TIO Flex支架来搭配现有Tiny主机和显示器设备,也可以一步到位,直接选择TIO Flex支架+显示器+Tiny主机的打包方案,实现成本和效益的平衡。

助力千行百业,从容应对智慧办公场景升级和生产力变革
作为一家深耕政、教、企,服务超过10万+家客户的科技企业,联想对于商用客户有着深刻的理解。面对如今需求收缩、供给冲击、预期转弱的三重发展压力,联想用TIO Flex这样一款具备超长生命周期的产品,帮助企业减轻采购成本,满足大中小型客户对于降本增效的需要,另一方面,在国家加快建设数字经济、数字社会、数字政府的大背景下,TIO Flex出色的扩展能力和适应能力,能够为企业开启数字化办公升级,解决行业场景数字化难题提供长期可靠的支持。

面对金融行业从传统柜台到智慧网点的转变,TIO Flex的出色场景适应能力,不仅能够满足特色场景网点的应用部署和形象需要,还能够成为客服中心、投资理财、金融展业等不同职能部门的办公帮手;在教育领域,TIO Flex适配联想一系列丰富的智慧教育生态,能够为教师备课提升效率,打造公平有质量的教育;在医疗领域,TIO Flex是柜台窗口、医生诊室、病房管理等众多场景的可靠帮手。
在TIO Flex背后是联想集智能硬件,软件生态,全生命周期服务三大能力的整体赋能。ThinkCentre Tiny诞生十周年之际,坚持科技赋能智能化转型的愿景,未来联想商用将继续立足行业需求,以长期主义坚持创新,做大做强“3 X(1+N )智慧办公解决方案”,帮助千行百业客户”智”胜办公新常态发展下的场景升级和生产力变革,成为客户可信赖的新IT Partner。
来源:业界供稿
好文章,需要你的鼓励


腾讯开源混元MT翻译模型系列
腾讯今日开源混元MT系列语言模型,专门针对翻译任务进行优化。该系列包含四个模型,其中两个旗舰模型均拥有70亿参数。腾讯使用四个不同数据集进行初始训练,并采用强化学习进行优化。在WMT25基准测试中,混元MT在31个语言对中的30个表现优于谷歌翻译,某些情况下得分高出65%,同时也超越了GPT-4.1和Claude 4 Sonnet等模型。

如何让AI像电影配乐师一样创作完整的长篇音频故事——腾讯ARC实验室团队AudioStory突破性进展
腾讯ARC实验室推出AudioStory系统,首次实现AI根据复杂指令创作完整长篇音频故事。该系统结合大语言模型的叙事推理能力与音频生成技术,通过交错式推理生成、解耦桥接机制和渐进式训练,能够将复杂指令分解为连续音频场景并保持整体连贯性。在AudioStory-10K基准测试中表现优异,为AI音频创作开辟新方向。

Unity Stoakes谈科技、科学与设计的融合变革全球健康
今年是Frontiers Health十周年。在pharmaphorum播客的Frontiers Health限定系列中,网络编辑Nicole Raleigh采访了Startup Health总裁兼联合创始人Unity Stoakes。Stoakes在科技、科学和设计交汇领域深耕30多年,致力于变革全球健康。他认为,Frontiers Health通过精心选择的空间促进有意义的网络建设,利用网络效应推进创新力量,让企业家共同构建并带来改变,从而有益地影响全球人类福祉。

Meta与特拉维夫大学联手打造VideoJAM:让AI生成的视频动起来不再是奢望
Meta与特拉维夫大学联合研发的VideoJAM技术,通过让AI同时学习外观和运动信息,显著解决了当前视频生成模型中动作不连贯、违反物理定律的核心问题。该技术仅需添加两个线性层就能大幅提升运动质量,在多项测试中超越包括Sora在内的商业模型,为AI视频生成的实用化应用奠定了重要基础。
2022
08/30
15:03
分享
点赞

腾讯开源混元MT翻译模型系列
Unity Stoakes谈科技、科学与设计的融合变革全球健康
微软结束OpenAI独家合作,Office将引入Anthropic模型
亚马逊推出Zoox无人出租车服务,在拉斯维加斯提供免费乘车体验
OpenAI与Oracle签署3000亿美元云计算合作协议
Akamai联合IDC研究:生成式AI驱动边缘演进,亚太80% CIO将依赖边缘服务支持AI工作负载
Gartner发布2025中国网络安全技术成熟度曲线
Lucidity将成本控制焦点转向Kubernetes存储
Spotify因万名用户出售数据构建AI工具而愤怒
Anthropic服务大规模宕机,开发者调侃重回"原始编程时代"
AI说谎的原因:它只是在迎合你想听的答案
量子计算创业公司PsiQuantum获得10亿美元融资,目标构建百万量子比特机器
